
I believe the central problem of the 21st century is how civilization co-evolves with science and technology. As our understanding of the world deepens, it enables technologies that confer ever more power to both improve and damage the world. There's currently much public discussion of this in the context of artificial superintelligence (ASI). However, it's a fundamental recurring challenge, affecting areas including climate change, genetic engineering, nanotechnology, geoengineering, brain-computer interfaces, and many more. How can we best benefit from science and technology, while supplying safety sufficient to ensure a healthy, flourishing civilization?
This essay emerged from a personal crisis. From 2011 through 2015 much of my work focused on artificial intelligence. But in the second half of the 2010s I began doubting the wisdom of such work, despite the enormous creative opportunity. For alongside AI's promise is a vast and, to me, all-too-plausible downside: that the genie of science and technology, having granted humanity many mostly wonderful wishes, may grant us the traditional deadly final wish. And as I grappled with that, I began seriously considering whether science and technology creates other existential risks (xrisks). Do we have the ideas and institutions to avert such risks? If not, should I be working on science and technology at all? And what should we collectively be doing about such risk?
This internal conflict has been unpleasant, sometimes gut-wrenching. As a scientist and technologist, my work is not just a career, it is a core part of my identity, intertwined with fundamental personality traits: curiosity, imagination, and a drive to understand and create. I have devoted my life to science. If pursuing science and technology is a grave mistake, then how should I change my life? I began considering changing careers or becoming an anti-AI activist. I also considered more symbolic actions, like taking offline my book about neural networks. But such actions seemed short-sighted and reflexive, not informed by a deep investigation of the underlying issues.
While these questions are personal, to answer them well one needs a big-picture view of how humanity should meet the challenges posed by science and technology, and especially by ASI. This essay attempts to develop such a big-picture view. It's an informal technical essay, long and discursive, a report on partial progress; an ideal public-facing version would be much shorter and more focused. But I needed to metabolize past thinking on the subject, and that's meant a lot of exploration. The value in retracing old paths is that it makes clear crucial questions that, when reconsidered, lead to novel ideas. The essay extends and complements, but may be read independently of, my earlier work on xrisk, particularly "Notes on Existential Risk from Artificial Superintelligence", "Notes on the Vulnerable World Hypothesis", and "Notes on Differential Technological Development".
For progress there is no cure… We can specify only the human qualities required: patience, flexibility, intelligence. – John von Neumann, in "Can We Survive Technology?"
Knowledge itself is power. – Francis Bacon, in "Meditationes Sacrae"
Let's begin with a simple heuristic model illustrating how science and technology impact the world. The underlying idea was stated in the preface: as humanity understands the world more deeply, that understanding leads to more powerful technologies, which give ordinary individuals1 and small groups more capability to impact the world, for good and ill2:
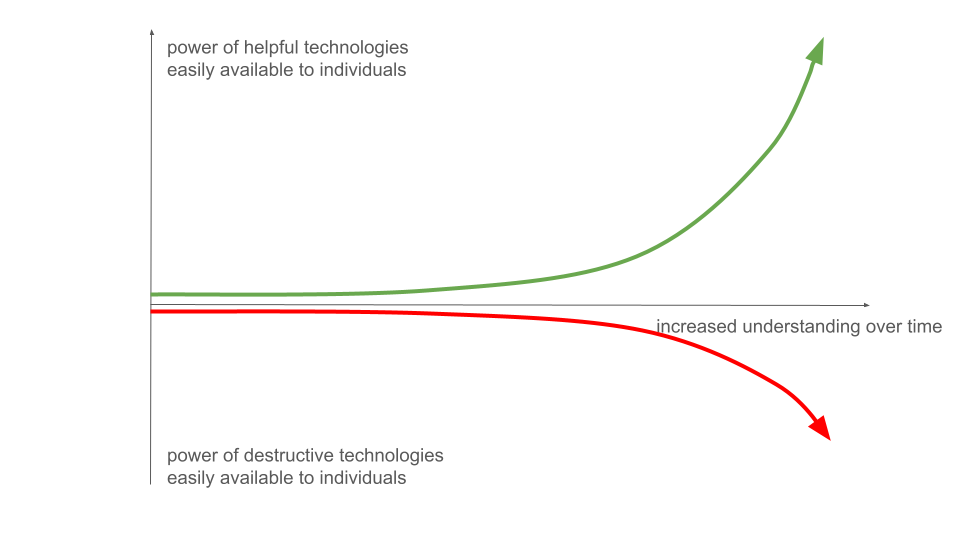
The positive curve gives us wonderful, life-enabling abilities. The negative curve destroys. Fortunately, today this destructive potential is limited. When someone like Anders Behring Breivik kills 77 people we grieve and we may alter laws and policing, but such an event is not a threat to humanity. However, it raises the question: as technology continues to advance, how much more damage could a single deranged individual or small group inflict? In the 1980s and 1990s the Aum Shinrikyo doomsday cult sought to develop or acquire weapons to kill nearly all humans; developing such weapons today is likely far easier than during Aum Shinrikyo's time. Although Aum Shinrikyo is gone, doomsday cults remain a threat3. Is humanity gradually developing tools that will democratize Armageddon? Does the heuristic graph above escalate to a civilization-ending level of dangerous technology?
This possibility has been considered many times throughout the history of science and technology, but it has become particularly contentious recently, with the rise of interest in AI, AGI, and ASI. Many thoughtful people are now warning of what they see as potential existential risk (xrisk)4 from ASI. Meanwhile, skeptics complain that the supposed risks sound like low-quality science fiction – entertaining stories, perhaps, but not well argued or likely to occur in reality. Understandably, they want to hear detailed, plausible scenarios before they take such xrisks seriously. On the other side: (a) there is a prudent caution about developing such scenarios in detail, lest it help bring about those very outcomes; and (b) we should, by definition, expect to fail to anticipate how an ASI would be capable of acting, since it will perceive possibilities we do not. It's a situation that seems difficult to resolve, except through enactment of an actual catastrophe.
I won't make a detailed argument for xrisk from ASI in this essay. Arguments both for and against have been discussed extensively elsewhere, and I refer you there5. I also haven't yet explicitly defined AI, AGI, or ASI. I discuss how I'm using the terms in the Appendix, but briefly: by "AGI", I mean a system capable of rapidly learning to perform comparably to, or better than, an intelligent human being, at nearly all intellectual tasks human beings do, broadly construed. By "ASI" I mean a system capable of rapidly learning to perform far better than an intelligent human being at nearly all intellectual tasks human beings do, broadly construed, subject to the constraints that "better" be reasonably well-defined, and humans are not already near the ceiling. (So noughts and crosses is out as a test, and somewhat subjective tasks like writing poetry are in a grey zone.) I intend no implication that today's LLMs are either close to or far from AGI. While I have opinions on that subject, they're weakly held and not relevant to this essay. I say this because sometimes when people talk about AGI or ASI, others change the premise, responding with "But LLMs can't […]" This is like making a claim about rockets, and having it "refuted" by someone discussing the properties of bicycles. Of course, if you believe we are many decades away from achieving AGI, then many concerns in this essay won't be of immediate interest. Personally, my weakly-held guess is that ASI is, absent strong action or disaster, most likely one to three decades away, with a considerable chance it is either sooner or later. "AI" I shall not use as a technical term at all, but rather as a catchall denoting the broad sphere of activities associated to developing AGI- or ASI-like systems.
While the plausibility of xrisk scenarios is disputed, there are some striking broad pathways toward catastrophic risk. Briefly6, let me list a few: easily constructed nuclear weapons, perhaps inspired by one of the Taylor-Zimmerman-Phillips designs7; easily-constructed antimatter bombs; destructive self-replicating nanobots – while the notion of "grey goo" is sometimes ridiculed, something like grey goo has happened at least twice on earth (the origin of life, and the great oxygenation event); large-scale computer security compromise, leading to failures or takeover of crucial systems (electric grid, banking, the supply chain, the nuclear strike capability, and so on). And then there's the risk many see as most imminent: biorisk, small groups deliberately or accidentally creating or discovering pathogens far more devastating than COVID-19. Unfortunately, this gets easier every year. Consider the accidental(!) lethalization of mousepox achieved in 2004 (and later essentially perfected, even against vaccinated mice)8. This has led to concern a similar mortality rate could be achieved in human smallpox through a similar modification. All these risks illustrate how, as we understand the universe more deeply, that understanding enables us to build more powerful capabilities into our technologies. This is a destabilizing situation, placing ever more power in the hands of ordinary individuals.
All these threat models are of concern, even if you ignore ASI. And I expect many more risks will be discovered in the decades to come. As mentioned in the preface, over the past few years I've increasingly felt uneasy about all my technical projects – science and technology itself seems to be the fundamental threat, not just ASI, and anything contributing to science and technology has come to seem more questionable. In 1978, Carl Sagan9 speculated that technical civilizations may inevitably kill themselves, although he holds out hope that not all is lost:
Of course, not all scientists accept the notion that other advanced civilizations exist. A few who have speculated on this subject lately are asking: if extraterrestrial intelligence is abundant, why have we not already seen its manifestations?… Why have these beings not restructured the entire Galaxy for their convenience?… Why are they not here? The temptation is to deduce that there are at most only a few advanced extraterrestrial civilizations – either because we are one of the first technical civilizations to have emerged, or because it is the fate of all such civilizations to destroy themselves before they are much further along.
It seems to me that such despair is quite premature.
In a similar vein, in 1955 John von Neumann wrote an essay10 whose title encapsulates the core concern: "Can we survive technology?" Although his concrete concerns mostly involve nuclear weapons and climate control – what today we'd call geoengineering – much of the argument applies in general, across technology, and von Neumann intended a general argument. Note von Neumann repeating one of the lessons of Prometheus and of the Sorcerer's Apprentice: the inextricable link between the positive and negative consequences of technology:
What could be done, of course, is no index to what should be done… the very techniques that create the dangers and the instabilities are in themselves useful, or closely related to the useful. In fact, the more useful they could be, the more unstabilizing their effects can also be. It is not a particular perverse destructiveness of one particular invention that creates danger. Technological power, technological efficiency as such, is an ambivalent achievement. Its danger is intrinsic… useful and harmful techniques lie everywhere so close together that it is never possible to separate the lions from the lambs… What safeguard remains? Apparently only day-to-day – or perhaps year-to-year – opportunistic measures, a long sequence of small, correct decisions… the crisis is due to the rapidity of progress, to the probable further acceleration thereof and to the reaching of certain critical relationships… Specifically, the effects that we are now beginning to produce… affect the earth as an entity. Hence, further acceleration can no longer be absorbed as in the past by an extension of the area of operations. Under present conditions it is unreasonable to expect a novel cure-all. For progress there is no cure. Any attempt to find automatically safe channels for the present explosive variety of progress must lead to frustration. The only safety possible is relative, and it lies in an intelligent exercise of day-to-day judgement… these transformations are not a priori predictable and… most contemporary “first guesses” concerning them are wrong… The one solid fact is that the difficulties are due to an evolution that, while useful and constructive, is also dangerous. Can we produce the required adjustments with the necessary speed? The most hopeful answer is that the human species has been subjected to similar tests before and seems to have a congenital ability to come through, after varying amounts of trouble. To ask in advance for a complete recipe would be unreasonable. We can specify only the human qualities required: patience, flexibility, intelligence.
This is a remarkable sequence of thoughts from one of humanity's greatest scientists and technologists. And, as the passage argues, much of the problem is intrinsic to science and technology broadly, not just ASI. However, ASI adds two challenges which make the concern much more urgent. First, it may accelerate the entire process, creating a kink in the heuristic curve illustrated above:
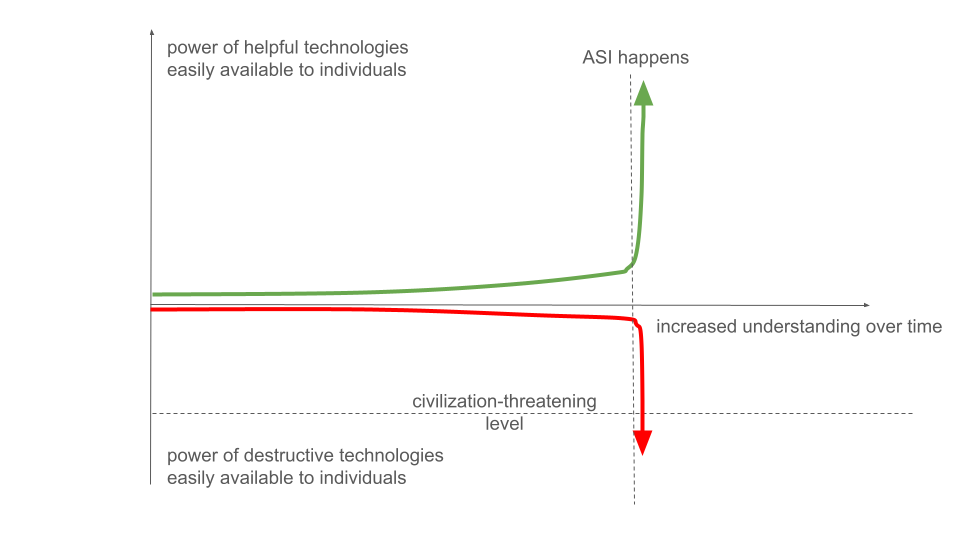
That is, ASI may hasten the day when an ordinary person or small group may misuse science and technology to cause catastrophic harm. Second, ASI may itself become a threat11, leading to a takeover by the machines (or a machine). This rogue ASI-taking-over-the-world model is much-discussed12, and sometimes taken to be the principal concern about ASI. However, a more important question is: how much power does the ASI system confer, either to its user, or to itself? An entirely obedient ("aligned") but extraordinarily powerful system could do a great deal of damage to humanity, if it was doing the bidding of a Vladimir Putin or Aum Shinrikyo. It doesn't matter so much whether the ASI has an operator or operates itself. People sometimes convince themselves that rogue scenarios won't happen, and therefore ASI will be okay. This conclusion is wrong, since the fundamental issue isn't control, it's how much power is conferred by ASI. To repeat von Neumann: "Technological power, technological efficiency as such, is an ambivalent achievement. Its danger is intrinsic." As a simple example of why this matters: some people believe technologies such as BCI and neurotech and intelligence augmentation will help address threats from ASI. Perhaps they may help against a rogue ASI, but they may also create novel risks for misuse, and thus have the opposite of the hoped-for effect.
(Why would ASI greatly speed up science and technology? Some people find this self-evident; others regard it as unlikely. I've discussed this in my "Notes on Existential Risk from Artificial Superintelligence", and will only make some brief remarks here. One objection comes from people who deny the premise of ASI, treating "ASI" as though it means "glorified LLM", not a system capable of superhuman intellectual performance in nearly all domains. This is a common enough objection to be worth mentioning, but it is not worth arguing. A more substantive objection is that scientific and technological progress is bottlenecked by factors other than intelligence. In this view, an army of super-Einsteins may help surprisingly little. It's sometimes pointed out that many people who believe ASI will cause a dramatic acceleration have little background directly contributing to science and technology, and don't always realize the extent to which science is not merely deduced from first principles; it depends upon a great many contingent facts in the world which must be observed, some over long timescales. Such bottlenecks can be reduced – robots could, for example, gather data on a much larger and faster scale than humans13. But all such bottlenecks can't be completely eliminated. My belief, discussed in my notes on existential risk, is that ASI will remove many of today's bottlenecks, greatly speeding up science and technology; however, new bottlenecks will arise (and may be obviated by later systems14).)
So: while my broad concern is the risk posed by science and technology, if ASI were not on the horizon, I'd likely put that concern aside, and leave it for future generations. We humans have, as von Neumann observes, done surprisingly well addressing the problems created by science and technology. But ASI makes this more questionable, especially if it speeds up the rate at which such problems are created. So for the remainder of this essay I focus on the impact of ASI, though I occasionally make remarks in the broader context. I have kept the title "How to be a wise optimist about science and technology?", since that framing is both important in its own right, and provides a powerful way of thinking about ASI in particular.
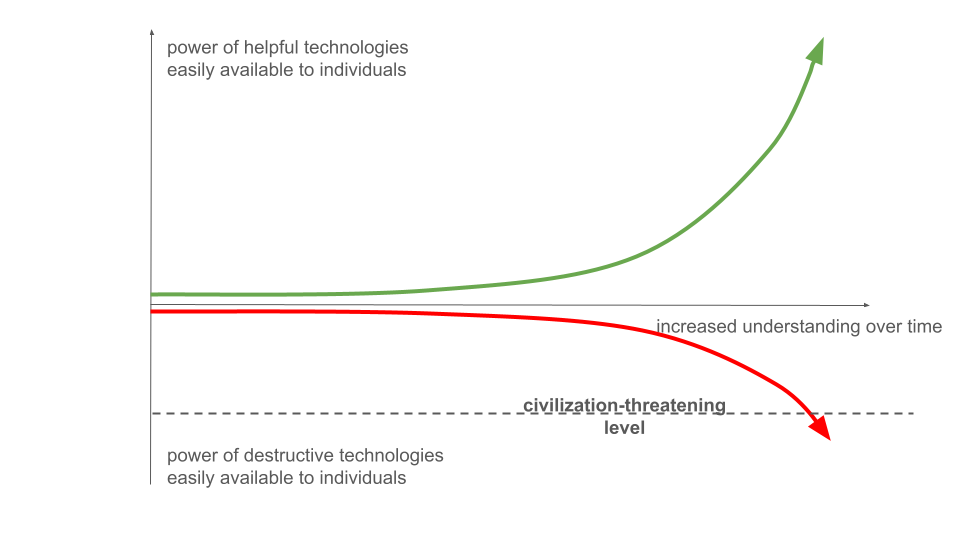
Let us consider again the horizontal line at which ordinary individuals or small groups can develop technologies posing catastrophic risk to humanity:
This is equivalent to the question of whether we will develop recipes for ruin15. Meaning: simple, easy-to-follow recipes that create catastrophic risk. Or in more detail: will we ever discover a simple, inexpensive, easy-to-follow recipe that an individual or small group with a typical education and typical resources can follow, which will do catastrophic damage to humanity16? Recipes for very large scale, cheap-and-easy antimatter bombs would fit the bill, for instance, or cheap-and-easy deadly pandemics.
Fortunately, today we don't know of any such recipe for ruin. But that doesn't mean none will ever be discovered. Many technologies that now seem familiar were once unimaginable. Consider how surprising human-initiated nuclear chain reactions must have seemed to the people who discovered them. Or, going back much further in history, how surprising fire would have been to people seeing it for the first time17. Neither nuclear bombs nor fires are recipes for ruin, but both have some characteristics of that flavour, and both must initially have been very surprising. Admiral William Leahy, Chief of Staff of the US armed forces at the end of World War II, called the atomic bomb project "the biggest fool thing we have ever done. The bomb will never go off, and I speak as an expert in explosives." This quote is sometimes used to illustrate the dangers of a lack of imagination; in fact, Leahy was both imaginative and technically competent. He had taught physics and chemistry at Annapolis, and knew the navy's weapons well. A better lesson is perhaps that the Hiroshima bomb seems a priori implausible: take two inert bodies of material –- each small enough to safely be carried by a single human being –- and bring them together in just the right way. If you'd never heard of nuclear weapons, it would seem obviously impossible that they'd explode with city-destroying force. You need to understand a tremendous amount about the world –- about relativity, particle physics, and exponential growth in branching processes –- before it is plausible. That novel and very non-obvious understanding revealed a latent possibility for immense destruction, one almost entirely unsuspected a few decades earlier. Similarly, it is entirely plausible that recipes for ruin may one day be discovered, and the only barrier is our current level of understanding18.
My experience is that the people who (like me) worry about xrisk from ASI (and, more broadly, from science and technology) are also those who instinctively believe recipes for ruin are likely to one day be discovered. It suggests it's just a matter of time. People who instinctively don't believe recipes for ruin are ever likely to be discovered are much more likely to be dismissive of xrisk. Here, for instance, is John Carmack refusing to consider the question. Perhaps this is motivated reasoning on Carmack's part, but he's too thoughtful and intellectually honest for me to believe that's likely. I suspect it's because different people acquire different bundles of intuition from their past experience, particularly their past expert training. Those bundles of intuition take thousands of hours to acquire, and vary greatly for different types of expertise – one is acquiring an entire expert subculture. And different bundles of intuition lead to very different conclusions about whether recipes for ruin are ever likely to be discovered. I suspect, for instance, this is why many economists don't find xrisk compelling – compared to a physicist or chemist they have very little feeling for how much potential lies hidden in the physical world, just as physicists and chemists often have poorly-developed intuitions about economics and scarcity.
Of course, it's reasonable to demand a detailed argument to support a claimed threat, not intuition from a subculture! Szilard and Einstein didn't go to FDR with an intuition about nuclear weapons, or tell him he needed to become a physicist; they went with detailed claims about which materials would be fissionable and why; how this would lead to a runaway process and to explosive force; what this had to do with German trade policy; and what American institutions should do. However, as I've discussed in detail elsewhere19, and mentioned above, there are intrinsic reasons it's hard to reason about the presence or absence of ASI xrisk in this way: (1) any pathway to xrisk which we can presently describe in detail doesn't require superhuman intelligence to discover; (2) any sufficiently strong argument for xrisk will likely alter human actions in ways that avert xrisk; and (3) the most direct way to make a strong argument for xrisk is to convincingly describe a detailed concrete pathway to extinction, but most people tend (naturally and wisely) to be hesitant to develop or share such scenarios. These three "persuasion paradoxes", especially the first, present a barrier to reasoning about risks from ASI in the usual ways.
All that said, my opinion is: if discovery continues to unfold under our existing institutions of technocratic capitalism, then recipes for ruin are likely to one day be discovered. I further believe ASI will likely greatly hasten the discovery of such recipes. I won't make a detailed argument – that would require conveying an entire culture, and would dwarf the rest of the essay. I do want to say a little about variations of the idea. A crucial question is: are recipes for ruin inevitable, given sufficient advances in science and technology20? Some people take this to be a question about the laws of nature – you might think it's simply a property of the universe. But it's more complex, since whether something is a recipe for ruin depends upon both: (1) the ambient environment (e.g., the presence or absence of some population level of immunity to a pathogen that would be deadly to some populations, and a non-event for others); and (2) the way in which we develop the technology tree21 (e.g., whether an effective missile shield is developed before or after large-scale multipolar deployment of ICBMs). With that said: there may be dominant recipes for ruin, that is, recipes for ruin which are extremely difficult to defend against, no matter the environment and other defensive technologies. If there's a cheap-and-easy recipe to create a large black hole on the surface of the Earth, then it seems likely the only protection is to suppress those branches of science and technology leading to such a recipe. Now, I'm not lying at night worrying about this particular example: I find such a recipe logically possible, but implausible. But what about some form of grey goo which is easily-created and hard-to-defend against? Unfortunately, that seems plausible and difficult to defend except by pre-empting development. It's happened before in the history of the earth, and we're not so far from being able to do it again. If it's easy to discover dominant recipes for ruin then that would certainly help explain why we don't see evidence of intelligent life writ large in the stars.
You may or may not accept those intuitions. As I said, whether you do will likely depend on your prior expertise. But intuition aside, for the remainder of the essay I will take as a basic premise that ASIs are likely to hasten the discovery of recipes for ruin, including recipes dominant against defenses; they can then be misused either by malevolent human or machine actors, creating xrisk for the human race. If you can't accept this premise, even for the sake of argument, then you won't find much of interest in this essay.
This line of thought made me deeply pessimistic for some time. But then, prompted by Catherine Olsson, I began to focus on the question: is it possible to be optimistic, even if you believe recipes for ruin may well be discovered by an ASI? Maybe even recipes dominant against plausible defensive systems? These questions matter because the future is made by optimists: they're the people with the vision and drive to act. In particular: good futures tend to be made by wise optimists, whereas bad futures are made by foolish optimists. For most of my life I've believed working to accelerate science and technology was the path of wise optimism. I'm now struggling with whether that belief was wise or, in fact, foolish. At the same time, I don't want fear of recipes for ruin to drive me into pessimism, an xrisk despondency trap22. There's no good future in that. Rather, I want to develop a wise optimism. This won't be an easy optimism – pessimism seems easier in response to a belief in recipes for ruin – but perhaps with enough active imagination it's possible to develop an optimistic point of view.
The basic intuition of the opening section was that science and technology keep increasing individual power, and this seems likely to eventually lead to individual humans (or individual machines) having enough power to destroy civilization. A problem with the heuristic is that over the past four centuries, just as science and technology has most increased individual power, we've also seen a gradual drop in interpersonal violence, and a general increase in safety, broadly construed23. Is the Armageddon heuristic wrong?
One common explanation for the ongoing increase in safety is that it's because of gradually increasing co-ordination and empathy and shared pro-social norms and institutions. The increase in effectiveness of these social technologies has actually outweighed dangers caused by the increase in individual power: humans have done a fantastic job increasing the supply of safety in the world. Even when very dangerous new technologies are introduced we find ways of ameliorating much or all of the danger. Perhaps that's how the heuristic model in the last section fails? Maybe there's some notion of the effective ability of an individual to do harm, and that hasn't changed so much; maybe it's gone up a little at times, gone down at others, without ever exploding:
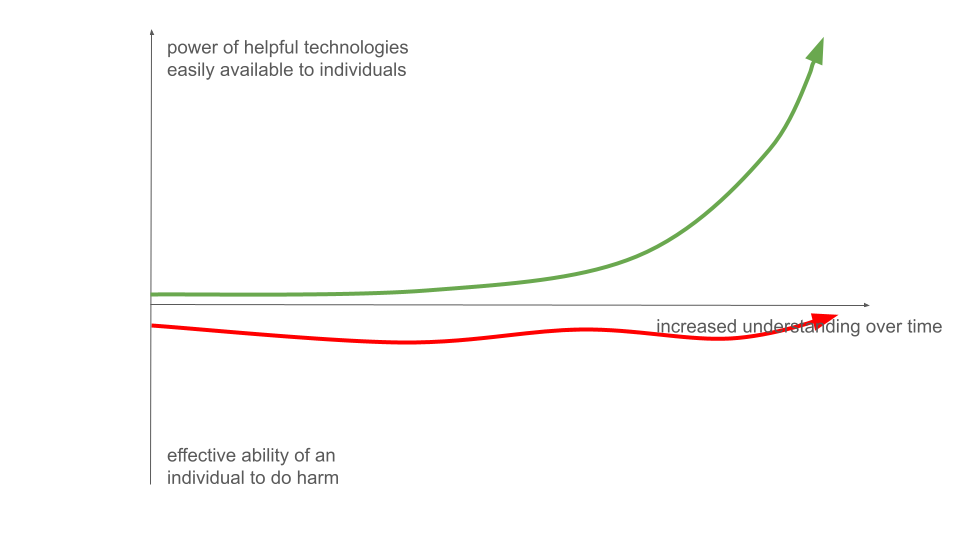
If you extrapolate out, this suggests a sort of long-run Kumbaya love-is-the-answer24 Teilhardian approach to ASI safety. Maybe we will go through a kind of phase transition25, in which individual sentient beings come to love one another – or, at least, co-operate with one another – so much that they no longer harm one another in serious ways.
While I've used over-the-top language for clarity26, it's only a slight caricature of the past few centuries. If you'd explained to William the Conqueror and Genghis Khan the state of the world in 2024 they would have been very surprised at how peaceful we are in co-existence. Yes, there are still terrible wars and violence. But detailed analyses show that violence has diminished a great deal. It's one of the glories of our civilization that our present institutions supply safety as well as they do. Most people today are simply much, much safer than people of former times. This gradual change has some similarities to the much earlier evolutionary transition in which individual cells stopped competing with one another, and instead all joined figurative hands to become multicellular organisms. AI researcher David Bloomin posed something like this to me as his basic picture of how ASI safety will happen. And Ilya Sutskever seems to believe something related: for a long time his Twitter biography read "towards a plurality of humanity loving AGIs". I don't think that's quite the right framing, but it's worth pondering, and I'll consider a variation later in this essay. Of course, it's going to take enormous additional ingenuity to supply sufficient safety in an ASI future; absent that, we may instead live (and then die) in the Armageddon future.
In this viewpoint, good questions about the progress of science and technology are: what controls the supply of safety? When does our species do a good job of supplying safety well? When do we supply it poorly? Are there systematic ways in which it is undersupplied? Are there systematic fixes which can be applied to address any systematic undersupply? Can we supply safety without causing stagnation? Do we need to modify existing institutions or develop new institutions to achieve this? These are core questions. I won't address them immediately: we're in too passive, too reactive a frame. But we will return to them later, from within a more active frame.
You may object that "Oh, using 'safety' as an abstract quantitative noun in this way is a category error, likely to be misleading." In 1989, Alan Kay made a pointed joke about a similar (mis?)use of the term "interface"27: "Companies are finally understanding that interfaces matter, but aren't yet sure whether to order interface by the pound or by the yard." A similar joke may reasonably be made about my usage of "safety" – should we order it by the pound or by the yard? But I think it's helpful, albeit requires some care, to view safety in this aggregated way28: it makes the point that safety is something that can be systematically over- or under-supplied by society's institutions29, and challenges us to think about what the right systems are for supplying it. This is a crucial mindset shift.
There's obviously tension between the Kumbaya and Armageddon heuristics. In public discussion of ASI one way that tension is expressed is through disagreement between two prominent groups: (1) the "accels" (sometimes misleadingly called "techno-optimists"), who believe we should accelerate work on ASI, and who are xrisk denialists, since they deny or minimize xrisk from ASI; and (2) the "decels" (or "doomers"), who believe ASI xrisk is considerable, and who are pessimistic about any solution apart from stopping development of ASI.
It's tempting to think these two groups correspond to the two heuristic models I just introduced: the accels believe the Kumbaya heuristic model, while the decels believe the Armageddon heuristic model. However, the situation is more complex than that. In particular, many of the accels not only believe the Kumbaya heuristic, they treat it as near inevitable. They mostly don't worry about the supply of safety – I've seen some celebrate the decimation of the safety team at OpenAI in 2024, for instance. They treat safety as easy, someone else's problem, something to free ride on, while the accels ride ASI to their own assumed glory. By contrast some decels not only believe the Armageddon heuristic, they are pessimistic that much can be done about it except slowing down or reversing our progress in understanding.
I am making broad assertions here about rapidly-changing, heterogeneous and sometimes incohesive social movements. "Accels believe this, decels believe that". My description is a coarse approximation; in reality it's "many accels believe this, many decels believe that". In any case social reality often changes rapidly, so what is true today may be false in a year. Still, these simple caricatures contain much truth, at the time of writing. Furthermore, regardless of how well (or poorly) this describes social reality, the primary reason I am discussing this is to highlight these two sets of distinct assumptions. Teasing apart those underlying assumptions will help us formulate alternative points of view.
In part because the accel-vs-decel classification has become so prominent, many people assume the only way to be optimistic about the future is to deny xrisk. I've heard many conversations which contain variants on: "Oh, you worry about xrisk, you're one of those pessimists". This assumption is not only false, it's actively misleading. It's entirely possible to believe there is considerable xrisk and to be optimistic. In Part 3 of this essay we'll develop a point of view which accepts that there is considerable xrisk from science and technology, but then asks: how can we develop a truly optimistic response? This is a wise optimism which understands that you don't get good futures either by denying risks or by responding fearfully and pessimistically. Rather, you get good futures by deeply understanding and internalizing risks, then taking an active, optimistic stance to overcome them. It's a wise optimism that understands the tremendous achievement the Kumbaya heuristic graph represents, and takes seriously the enormous additional ingenuity that will be needed to supply sufficient safety in an ASI future. While that's a much harder and more demanding optimism, over the long run it's far more likely to result in good outcomes.
By contrast, while the accel xrisk denialists style themselves as optimists, if there really is xrisk then theirs is a foolish optimism, one likely to lead to catastrophe. It's like someone diagnosed with cancer deciding that they're going to "choose optimism", deny the cancer, and carry on as though nothing is wrong. These are the ideological descendants of those who brought us what they maintained were the gifts of asbestos and leaded gasoline.
The "wisely optimistic" view we'll develop is related to views held by some AI safety researchers at AGI-oriented companies. But as we'll see it goes further than is common in focusing not only on the safety of AI systems, but also on: (a) non-market aspects of safety which the market either won't supply or is likely to oppose; and (b) aspects of safety which aren't interior to the technologies being built, but are distributed through society and, indeed, the entire ambient environment, up to and including the laws of nature. We'll call this point of view coceleration, since it involves the acceleration of both safety (very broadly construed) and capabilities. As we'll see, it isn't an easy optimism, and requires tremendous active imagination and understanding. But it is plausibly the path of wise optimism.
Man is a very small thing, and the night is large, and full of wonder. – Lord Dunsany
So far we've focused on framing the problems facing humanity: how to ensure safety amid the progress of science and technology? We'll return to that in Part 3. I want now to switch to a future-focused imaginative mindset, one where we ask: what is the opportunity in the future? In, say, 20 or 50 or 100 or 200 years? Can we imagine truly wonderful futures, insanely great futures, futures worth fighting for?
Of course, imagining our future is a task for our entire civilization, not a short text! But we can at least briefly evoke a few points in the space of future possibilities. This is not a prediction of what will happen; it is rather an evocation of what we might potentially make happen, a few points on an endless canvas that can only be filled out by further imagination and an incredible amount of work. Nor is it a utopia: there's no narrative, much less a strong underlying theory of development. Nor will I justify the possibilities described, or even describe them in much detail. This is a limitation: all the possibilities below require immersion in extended discussion to really understand, let alone to comprehend the implications. However, the intent here is to forcefully remind myself (and readers) that we are, as David Deutsch has so memorably put it, at "the beginning of infinity". While the space of possibilities is far larger than we currently imagine, it's worth recalling just how large the space is that we currently can imagine!
Many prior sketches of the optimistic possibilities of the future have been written. I won't attempt a survey – this can't be both an evocation of possibility and an academic list of citations – but I want to note an ASI-adjacent surge of such sketches recently, from people including OpenAI CEO Sam Altman, Anthropic CEO Dario Amodei, the philosopher Nick Bostrom, and tech investor Marc Andreessen. While these are not disinterested observers, they are welcome in that understanding the threat posed by science and technology requires also a strong sense of the possibility of the future30.
So: what might we see in the future, given that we're still at the beginning of infinity? Imagine an incredible abundance31 of energy, of life, of intelligence, but most of all of meaning32, far beyond today. Imagine it as a profusion of new types of qualia, new types of experience, new types of aesthetic, and new types of consciousness, as different to (and as much richer than) a human mind as a human mind is different to a rock. Imagine it as a profusion of new types of identity and new types of personality. Imagine it as new ways of changing, merging, fracturing, refactoring identity and personality. Imagine it as wildly expanded notions of intelligence, of consciousness, of ability to be and to act and to love, in a million different flavours. Imagine it as a multitude of new ways to co-operate and co-ordinate and come to agreement, far beyond any individual.
Imagine it as ASI, BCI, uploads, augmentation, uplifting, new cognitive tools, immune computer interfaces33, metagenome computer interfaces. Imagine it as a profusion of new phases of matter, with properties currently inconceivable, the creation of phases of matter as a true design discipline, fully programmable and with a rich, composable design language. Imagine it as universal constructors, femtotechnology, utility fogs, a shift from uncovering the rules underlying how matter works to, again, a design point of view, in which we use those rules to make matter fully programmable. Imagine it as abstractions to describe entirely new types of matter, an interface direct to the laws of physics, of chemistry, of biology, and all the levels beyond. Imagine it as a billion new types of object and material and actions and affordances in the world34.
Imagine it as an end to hunger, an end to suffering, an end to apathy and ennui, an end to unnecessary illness and death, an end to the agony of aging and decay. Imagine it as sentience through all of space and into the far-distant future.
Imagine it as a loving plurality of posthumanities.
We humans currently use an infinitesimal fraction of the available energy, mass, space, time, and information resources. We use, for example, about 200 Petawatt Hours of energy each year; the sun outputs more than ten trillion times as much energy, about 3 million billion Petawatt Hours each year. The solar system is vast beyond our comprehension. And yet it is a tiny speck in our galaxy, itself a tiny speck in the universe as a whole.
The physical world is immense.
Imagine that immense physical world as our playground for the future, something we can gradually learn to harness as the basis for imaginative design.
In the biological world, we are (again) near the very beginning. We have, for example, only just attained a basic understanding of a tiny handful of well-studied proteins, such as hemoglobin and kinesin. And yet billions of proteins have been identified in nature, a smorgasbord of molecular machines, containing myriad secrets of both principle and practice. It's as though we've just stumbled upon an incredibly advanced alien microscopic industrial civilization, which we now get to study and learn from.
The biological world is immense.
Imagine that immense biological world as our playground for the future, something we can gradually learn to harness as the basis for imaginative design.
Barring a dramatic slowdown, I believe the 21st century will see our transition to a posthuman world35. I hope it will be a world where sentience blooms into myriad forms, coexisting harmoniously in a state of loving grace. And, as a partisan of humanity, an optimistic vision does not mean a world without humans, but rather one including human beings as well as many new types of sentience. What astonishing possibilities are there in such a world? How can we imagine and move toward such a world of abundance?
In this section I've eschewed the language of prediction, focusing instead on imagination and possibility. This contrasts with much AI safety discourse, which is often framed in terms of timelines, probabilities of doom, prediction markets, and so on. I've avoided this predictive viewpoint in part because it's the passive view of an outsider, not a protagonist; and in part because it de-centers imagination. ASI isn't something that happens to us; we control it. Timelines are something we are collectively deciding. To do that well we must see ourselves as active imaginative participants, not merely passive or reactive respondents. The predictive viewpoint should serve the imaginative viewpoint, not vice versa. That's why I've deliberately centered the imaginative viewpoint: imagination is more fundamental than prediction. If people such as Alan Turing and I. J. Good hadn't imagined AGI and ASI we wouldn't be discussing predictions related to them. Imagining the future well is both extraordinarily challenging and an extraordinary opportunity.
Reflecting on this section, I feel four sources of discontent. First, the speculative, impressionistic style lacks concrete detail. However, it is not enough to worry about safety and disaster; to understand those well we must also understand the optimistic possibilities (and vice versa). Still, while the evocation is (necessarily) not in-depth, I believe it's useful as a starting point for more in-depth consideration. Second, the section is too focused on technology and material conditions, with no rich evocation of new possibilities for experience or meaning or social organization. Those are at least as important as technology and the material world, but even harder to imagine. Third, I emphasize technology as a means of improving humanity's lot; some people see progress instead in a retreat from technology, making space for different values and forms of abundance36. I've emphasized the pro-technology approach in this section because the remainder of the essay takes a more critical stance. Fourth, in writing this section I am frustrated my own poverty of imagination. Humanity truly is at the beginning of infinity, but how dimly we perceive it! Imagining the future well is hard work, and our design discipline of the future is still nascent. We have devoted insufficient rigorous effort to imagining posthuman futures, resulting in a meager shared posthuman canon. We must change this for posthumanity to go well.
If our shared vision of the opportunity of the future is impoverished, then how can we develop a richer shared vision of the future? In this section I explore one approach to this problem. It's tangential to the main line of the essay, and the section may be skipped without affecting the main argument. Let me start elliptically. If you go to certain parties in San Francisco, you meet hundreds (and eventually thousands) of people obsessed by AGI. They talk about it constantly, entertain theories about it, start companies working toward it, and generally orient their lives around it. For some of those people it is one of the most important entities in their lives. And what makes this striking is that AGI doesn't exist. They are organizing their lives around an entity which is currently imaginary; it merely exists as a shared social reality.
Where did this imaginary entity originate? While I won't give a detailed history, it's the imaginative product of many minds. The 1950s were particularly fertile, the time when Alan Turing wrote his famous paper introducing his test for machine intelligence. It's the time when John McCarthy coined the term "Artificial Intelligence". It's when McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon ran the first workshop on AI. It's a little after Isaac Asimov began to write his stories about artificially intelligent robots. And, of course, long after stories like Mary Shelley's "Frankenstein", Samuel Butler's "Erewhon", and other similar progenitors.
Some of those people built simple prototype systems – Shannon, for example, built a machine to play a simplified version of chess. But their work was largely conceptual. They used their imagination and understanding to invent hypothetical future objects – things they believed could exist, but which didn't at the time. Indeed, not only did those hypothetical objects not exist, these people had only a dim idea of how they could be built. But they saw the broad possibility, and described it concretely enough to make it a viable goal. Subsequent decades saw many small steps toward that goal made by scientists. In parallel it also saw a tremendous amount of imaginative science fiction, fleshing out and exploring what AI could mean.
I use the term hyper-entity37 to mean an imagined hypothetical future object or class of objects. AI is just one of many hyper-entities; closely related examples include AGI, ASI, aligned ASI systems, mind uploads, and BCI. Outside AI, examples of hyper-entities38 include: world government, a city on Mars, utility fog, universal quantum computers, molecular assemblers, prediction markets, dynabooks, cryonic preservation, anyonic quasiparticles, space elevators, topological quantum computers, and carbon removal and sequestration technology39. Even on-the-nose jokes like the Torment Nexus are examples of hyper-entities. Many important objects in our world began as hyper-entities – things like heavier-than-air flying machines, lasers, computers, contraceptive pills, international law, and networked hypertext systems. All were sketched years, decades, or even centuries before we knew how to make them. But they ceased to be hyper-entities when they were actually created, sometimes rather differently than was expected by the people who originally imagined them. By contrast, things like dragons or unicorns, while imagined objects, are not examples of hyper-entities, since they aren't usually considered to be future objects. There are related hyper-entities, though: "genetically engineered dragon" is an example.
The most interesting hyper-entities often require both tremendous design imagination and tremendous depth of scientific understanding to conceive. But once they've been imagined, people can become invested in bringing them into existence. Crucially, they can become shared visions. That makes hyper-entities important co-ordination mechanisms. The reason AGI is a subject of current discussion is that the benefits of AGI-the-hyper-entity have come to seem so compelling that enormous networks of power and expertise have formed to bring it into the world. It's become a shared social reality. This is a common pattern with successful hyper-entities. While still imaginary, they may exert far more force than many real objects do40. As a result, the futures we can imagine and achieve are strongly influenced by the available supply of hyper-entities. This makes the supply of hyper-entities extremely important: they determine what we can think about together; they are one of the most effective ways to intervene in a system; a healthy supply of hyper-entities helps pull us into good futures. If all we imagine is bad futures that's likely what we'll get41.
To see how much this matters, it's worth pondering what would happen if as much effort was applied to other hyper-entities as is currently being applied to AGI. I don't just mean money; I mean work by a multitude of brilliant, driven, imaginative people, each of whom believe ASI is going to happen, and is working hard to find some special edge. And this has mobilized tens of billions of dollars and enormous ingenuity to the task. What if the same level of social belief – and thence of ingenuity – was brought to bear on, say, immune computer interfaces? Or cryonics? I believe progress on those hyper-entities would dramatically speed up; they might well become inevitable. In this sense, shared belief is the most valuable accelerant of AGI today. And we can flip this around and ask: what if AGI became as socially unpopular as (say) the Vietnam War became in its later stages? What if it became more unpopular than the Vietnam War? It seems likely that, at the least, AGI would be considerably delayed.
The term hyper-entity is related to the notion of a hyperstition, introduced by the accelerationist philosopher Nick Land in the 1990s42. As summarized by Wikipedia, hyperstitions are ideas that, by their very existence as ideas, bring about their own reality, often through capitalism43, though sometimes through other means. In a 2009 interview, Land describes a hyperstition as:
a positive feedback circuit including culture as a component. It can be defined as the experimental (techno-)science of self-fulfilling prophecies. Superstitions are merely false beliefs, but hyperstitions – by their very existence as ideas –- function causally to bring about their own reality. Capitalist economics is extremely sensitive to hyperstition, where confidence acts as an effective tonic, and inversely. The (fictional) idea of Cyberspace contributed to the influx of investment that rapidly converted it into a technosocial reality. Abrahamic Monotheism is also highly potent as a hyperstitional engine. By treating Jerusalem as a holy city with a special world-historic destiny, for example, it has ensured the cultural and political investment that makes this assertion into a truth… The hyperstitional object is no mere figment of ‘social constuction [ sic ]’, but it is in a very real way ‘conjured’ into being by the approach taken to it.
Of course, an object may be both a hyperstition and a hyper-entity. However, Land's notion of hyperstition is focused on how it is socially and culturally self-realized: as the -stition suffix indicates, it's primarily a belief. For us in our concern with hyper-entities, while belief and self-realization are interesting possibilities they are not central. A hyper-entity may be strongly socially self-realizing, or not at all. Rather, we are focusing on the design properties – what the hyper-entity can do, and how it can do it, not on the social means by which it is realized. This perhaps seems more quotidian, but I believe the history of technology shows that often it is the design properties that are most interesting – the new affordances a hyper-entity enables – rather than the means of realization. As an example: the concept of a universal assembler is an extremely interesting hyper-entity, but (currently) it is arguable whether it could reasonably be called a hyperstition.
Where do new hyper-entities originate? There are a few common sources: basic science; design; futurism or foresight studies; science fiction; venture capital and the startup ecosystem44. My impression – I haven't done a detailed study – is that all make some contribution. The most common pipeline seems to be: basic science → (not always, but sometimes crucially) science fiction → academic science or hobbyist communities → investment-backed startups. Design, futurism and foresight studies play relatively smaller roles, perhaps because they're more oriented toward client work, and as a result rarely engage as deeply with basic science.
Many important hyper-entities originate in what I have called vision papers45. This includes universal computers, AGI, hypertext systems, quantum computers, and many more. Vision papers are a curious beast. They typically violate the normal standards for progress in the fields from which they come; they often contain no data; no hard results of the type standard in their fields; rather, they merely imagine a possibility and explore it. Alan Turing's paper on AI is a classic of the genre. It's often difficult to write followups to such papers; such followups tend to feel like speculation piled upon speculation. As a result of these properties, vision papers are surprisingly uncommon. The response of scientists to such papers is sometimes "why don't you do some real work, not this abstract philosophizing?" It's tempting to vilify academic science for this response, but much of the power of academic fields comes from their ability to impose (field-specific) standards for what it means to make incremental progress. Those field-specific standards of progress are extraordinarily precious, some of humanity's most significant possessions, and vision papers often violate those standards. It seems to me that creating high-prestige venues for such vision papers would potentially substantially increase their supply, while preserving the standards of the underlying fields. This might mean a journal of vision papers; it might mean something like a Vision Prize. It is also interesting to consider creating an anti-prize, perhaps the Thomas Midgeley Prize, to be "awarded" to the individuals whose invention has most damaged civilization.
Science fiction is sometimes mentioned as a place where hyper-entities originate. The most commonly cited example is likely Arthur C. Clarke on geosynchronous satellites, though in fact Clarke was popularizing an idea proposed earlier by Herman Potočnik. A still clearer example is Vernor Vinge on the Singularity; while Vinge did not originate the notion of the Singularity, he did write the deepest early essays and stories about the idea. Much of the most valuable exploration and development of many hyper-entities – including ASI, BCI, and many more – has been done through science fiction. The present essay has benefited: it would be much impoverished in a world without Butler's Erewhon, Asimov's Robot stories, the works of Vernor Vinge, and many more.
However, science fiction has two major problems as a source of hyper-entities. One problem is that it tends to focus on what is narratively plausible and entertaining; neither of these results in good hyper-entity design. It is, for example, very easy and often narratively useful to write about a "faster-than light drive" or a "perpetual motion machine"; unfortunately, that ease-of-writing does not necessarily correspond to ease-or-even-possibility-of-existence. Good hyper-entity design requires both deep insight into what is possible, and also checking against extant scientific principles. This kind of checking is done in first-rate vision papers; but it doesn't make for good narrative, nor is it usually regarded as entertaining, and so it's not typically demanded by the conventions of science fiction.
A second problem with science fiction as a source of hyper-entities is that science fiction authors are often not deeply grounded in the relevant science. They just won't have the depth of background to invent something like anyonic quasiparticles or universal computers. Such discoveries emerged out of truly extraordinary insight into how the world works. And insofar as nature is more imaginative than we, we should expect far greater opportunities to lie latent within such an understanding of nature than anywhere else. For that reason, I expect basic science will remain the deepest source of hyper-entities.
What would a serious practice of hyper-entity design look like? It would be deeply grounded in science. It would ultimately look for falsifiability and check against known principles, not narrative plausibility or entertainment. It would look for powerful new actions, powerful new object-subject relationships. It would be especially oriented toward discovering fundamental new primitive objects, affordances, and actions. In this it would be similar to interface and programming language design, but broadly across all the sciences, not constrained to the digital realm. This kind of imaginative design of new fundamental primitives is shockingly hard; in my admittedly limited experience46, it makes theoretical physics seem easy. Finally, such a discipline would be connected to a pipeline of later development.
I began this section with the question: how could we develop a much richer shared vision of the future? That question was motivated by the relative poverty of vision in the last section. As far as I can see, we have almost no serious discipline of imagining the future. What were people like James Madison, Alan Turing, and Jane Jacobs doing when they imagined the future? How to imagine good as opposed to bad futures? Some will object that there are already serious or at least nascent disciplines associated to predicting, forecasting, and influencing the future. That's fair enough, but it seems to me that when it comes to imagining the future we're much less serious. And, as emphasized in the last section, all those other activities are downstream of that act of imagination, since that's how we both reason about and co-ordinate to make the future47.
While I don't know how to imagine good futures, I do know that hyper-entities are a piece of the future we have experience in supplying. They're sufficiently narrow that they can be reasoned about in detail, and can be the focus of large-scale co-ordination efforts. I believe we can aspire to develop a good design discipline of hyper-entities, one which helps us imagine better futures (including safer futures). I think we're a long way from such a design discipline, but it's a worthy aspiration, and would help in expanding our conception of possible positive posthuman futures. And ideas like a vision journal or Vision Prize or Midgeley Prize would potentially help48.
I sometimes speak with naive builders – often engineers or startup founders – who think of hyper-entities as somehow "obvious". That's true of some hyper-entities, but it's not true of many of the most important; a concept like ASI seems obvious today, due to familiarity, but was not obvious historically. A related misconception is that all the good hyper-entities were conceived by builders. That's not even close to true. Sometimes, the conception of a new type of object and the implementation come from the same person or group – I believe this was true of the scanning tunnelling microscope, for instance. But very often a Tim Berners-Lee needs a Ted Nelson, or multiple Ted Nelsons, to come before them, preparing the conceptual path49. The skills required to imagine hyper-entities in the first place are often very different from those required to build them. David Deutsch was an excellent person to imagine quantum computers; he is not at all the right person to build them, as he is happy to acknowledge. Ditto Bose, Einstein, and Bose-Einstein Condensation. Or Alan Turing and Artificial Intelligence.
Relatedly, I've often encountered self-styled AI builders who pooh-pooh conceptual work, especially the conceptual work done by much of the AI safety community. "A bunch of bloggers". "Wordcels". "It's all just talk and academic handwringing, none of it results in real systems". "The future belongs to those who build!" "Nothing has come out of all that philosophy or Less Wrong stuff, it's all from real hackers / companies". "A bias to action!" And when you talk more to those builders, they mention ASI, and timelines, and FOOM, and alignment, and compute overhang, and slow takeoffs, and multipolar worlds, and the vulnerable world, and what it means to have a good Singularity. They live inside a conceptual universe that has been defined in considerable part by many of the people they deride. Indeed, they often even forget that AGI is a concept out of the imagination of Alan Turing and a few others – including people like Nick Bostrom – conceived in work of the kind they dismiss. But it's so compelling that they've become caught in that construct. It's a kind of builders' myopia. One is reminded of Keynes in a very different context: "Practical men, who believe themselves to be quite exempt from any intellectual influences, are usually the slaves of some defunct economist. Madmen in authority, who hear voices in the air, are distilling their frenzy from some academic scribbler of a few years back…. it is ideas, not vested interests, which are dangerous for good or evil." Of course, AI-related hyper-entity design isn't exactly coincident with what the AI safety community has been doing, but there is significant overlap. And deep conceptual work aimed at imagining good futures is of the utmost importance to achieving good futures.
In Part 2, I attempted to evoke a few mostly-positive elements of a posthuman future. Of course, as discussed in Part 1, important new technologies often create major disruptions, sometimes even catastrophes: consider the discovery of bronze; of iron; of agriculture; of democracy; of gunpowder; of the printing press; of social media; of added sugar in food; of asbestos; of oil; of aircraft; of nuclear weapons. Each caused major problems (and some had major positive consequences too). Whether the elements of a posthuman future which I have evoked are healthy depends upon our ability to adapt to the problems they create.
One approach to addressing these issues is through the concept of Differential Technological Development (DTD). Informally, this means ensuring defensive technologies progress more rapidly relative to offensive. A fuller 2019 definition by Bostrom50 reads as follows: "Retard the development of dangerous and harmful technologies, especially ones that raise the level of existential risk; and accelerate the development of beneficial technologies, especially those that reduce the existential risks posed by nature or by other technologies." It can be difficult to determine which technologies are harmful and which are beneficial, but this definition is at the least a useful conceptual step.
The Alignment Problem was introduced51 in the context of artificial intelligence. But a similar problem applies more generally to science and technology, and I recently52 gave a more general formulation: "the problem of aligning a civilization so it ensures differential technological development, while preserving liberal values". For good futures, civilization must continually solve the Alignment Problem, over and over and over again; it must always be supplying safety sufficient to the power of the technologies that it develops. It's not a problem to be solved just once, but rather a systematic, ongoing problem that requires continual solution. Indeed, even if a society of ASIs arose that wiped out all human beings, that society would itself still face the Alignment Problem. Violence and concentration of power would still be likely to tear such a world apart. The obvious point to wonder about in the Terminator movies is: even if the machines win, what prevents them from turning on one another? Without strong moderating influences, they will self-extinguish. The extent to which any society, human, non-human, or mixed, is able to survive and flourish is determined by the quality of its solution to the Alignment Problem.
There are many challenges in making the terms introduced above precise: how can we determine which technologies are dangerous or offensive; which technologies are defensive or beneficial; what does it mean to supply safety; what count as liberal values53; what does it mean to absolutely prioritize? And so on. I have addressed some of these questions in small part in earlier work54, but the bulk of the issue remains. With that said: for early-stage conceptual work, it's often useful to leave terms relatively loosely bound; as you apply them in practice you can iteratively improve the quality of the definitions55. This requires getting into the details of many concrete examples. For now, for conceptual sketching, we will leave the terms loosely bound.
Fundamental questions related to the Alignment Problem are: what systems does our civilization use to supply safety? In what ways is safety systematically undersupplied? How well are we solving the Alignment Problem? A certain kind of free market believer tends to believe safety will be well supplied by the market as new technologies are introduced. This is well illustrated by partial failures of the point. For instance: the world's first commercial jet aircraft was the de Havilland Comet. Three Comet aircraft crashed in the first year; unsurprisingly, sales never recovered, and the Comet was discontinued. However, other companies developing jet aircraft paid close attention, and learned to make much safer aircraft. While the crashes of the Comet were a tragedy, the rapid adaptation of the market was healthy. In cases like these there is a strong and rapid safety loop operating: when risks are borne immediately and very legibly by the consumer, the market is well aligned with safety, and supplies it well. Put another way: capitalism amplifies safety when dangers immediately and visibly impact the consumer, as in the case of the Comet. In this view it is unsurprising modern airlines are extraordinary paragons of safety. Indeed, in many markets anticipation of this feedback effect helps ensure that products are very safe even before the first version gets to market; the analogue of the Comet crashes never even happens in such cases. This has happened in many markets (often with a regulatory assist), from food to toys and even to the early AI models: techniques such as RLHF, Constitutional AI, and the work coming out of the AI Ethics and Fairness community are all examples of the safety loop operating, in part due to market incentives.
By contrast, when no consumer is bearing an obvious immediate cost, the market often supplies safety much less well. Markets often amplify technology which seems to benefit consumers, but has large hard-to-see downsides, sometimes borne collectively, sometimes borne in hard-or-slow-to-see ways by consumers. Examples include CO2 emissions, asbestos, added sugar in food, leaded oil, the pollution caused by internal combustion engines, CFCs, privacy-violating technologies, and many, many more. This tends to happen when the risks involve: externalities; long timelines; are illegible or hard to measure; are borne diffusely, perhaps damaging the commons; when it is hard to establish property rights in the harm; damage to norms or values. Those of an economic mindset sometimes simplify this down to "externalities", but this is an oversimplification. However, insofar as collective safety can be (imperfectly) modeled as a public good, we'd expect it to be undersupplied by the market.
(I cannot resist a digression on the fascinating case of CFCs, from which much can be learned. Early refrigerators used ammonia as a refrigerant; this sometimes leaked, killing people. As a result, manufacturers switched to CFCs, an instance of the market working well to reduce immediate risks. Unfortunately, the switch caused a much less legible risk to the commons – damage to the ozone hole – which took decades to understand. This was then resolved by collective action in the form of the Vienna Convention and then the Montreal Protocol, which mandated a worldwide switch from CFCs to HFCs. However, while this collective action is mostly the result of government and NGO action, it had a fascinating and important market component: Du Pont was the world's largest maker of CFCs, and might well have opposed the switch, but after some dithering announced that they supported it. This was in their self-interest, albeit in part because of considerable foresight for which they deserve credit: they'd begun a search for CFC substitutes more than a decade earlier, and were poised to also become a major player in the new market for HFCs. Other manufacturers fell into line. It's as though Saudi Aramco and Exxon-Mobil were set to become the world's largest renewable energy companies, due to their foresight and commitment to renewable energy. It's interesting to speculate on what would have happened had the switch away from CFCs been opposed by Du Pont and others. The Vienna Convention and Montreal Protocol were exceptionally successful – the first treaties ratified by every UN State. Would that have been the case if Du Pont had strongly opposed HFCs?)
In general, we will define the non-market parts of safety as those which are not in short-term commercial interests to supply. A simple example is that seatbelt laws were, for a long time, opposed by many automobile companies. Many of the biggest challenges our civilization has faced (or faces) are examples of cases where the non-market parts of safety dominate. When I was growing up, teachers told me I'd likely die due to: nuclear war; climate change; acid rain; the ozone hole; or one of several other ailments. What unites these ailments is that they didn't have obvious market solutions. Sometimes it was because they were largely outside the market (e.g., nuclear weapons). And sometimes it was because in the short term, the market was actually contributing to such problems, e.g., people burning oil as they drive cars has contributed to climate change. This makes the situation seem quite hopeless. Fortunately, in each case we've found ways to build bespoke non-market mechanisms to close the safety loop. And, slow as it might seem, we've made considerable (though often not enough) progress on nuclear war, pollution, climate, acid rain, the ozone hole, and so on.
Achievements like the nuclear non-proliferation treaty, the Clean Air Act and its analogues in non-US countries, and the Vienna Convention and Montreal Protocol are among humanity's greatest achievements. There's a striking common basis for the safety loop in each case: the worse the anticipated threat – a constructed collective epistemic state56 – the better humanity is able to respond. Many major (and minor) problems have been solved this way; it is arguable that this kind of safety is among our greatest social technologies. It's easy to take for granted, but notable that other animals can't operate such a safety loop. But while it's good we have made progress, our response to problems like nuclear war or climate change has not yet been sufficient. And it becomes worse with things like ASI where there are enormous barriers to agreeing on the threat. Indeed, we're beginning to see some (though not all) market actors deliberately sow doubt about the threat, not due to reasonable doubts, but due to their self-interest. In this it mirrors climate and many of the other examples above. As we'll see in the next section, while we should expect market forces do a good job of supplying some kinds of safety related to ASI, for many others it means organizations acting against their own short-term interest. To continue solving the Alignment Problem we desperately need institutions which do a better job supplying safety.
I've been describing the Alignment Problem as a collective societal issue. It may also be given an individual framing. A society tends to get what it rewards with success; it must therefore be careful what it rewards with success57. This suggests the Alignment Problem for Individuals: achieving a society in which individuals pursuing their own "success" tend also to be contributing to the good of that society58. Of course, "individual success" and "good for society" will never be more than partially aligned; we won't ever fully solve the Alignment Problem for Individuals. But much of the improvement in a civilization comes from better aligning the two, and continuing to align the two. Ideally, even sociopaths acting entirely in their own self-interest will serve the common good; wise, intelligent pro-social people will be especially successful. This was one of Adam Smith's most extraordinary insights – that people acting in their own self-interest in a market economy may also serve the common good. Indeed, this is the primary justification for today's market economy – a point sometimes forgotten or not acknowledged by free market maximalists59. AGI places significant pressure on this alignment: starting or joining an AGI startup is certainly in individuals' self-interest, but may be against our civilization's interest. I believe that if we can solve the Alignment Problem for Individuals, then all else will follow. This is yet another reason to care about problems like climate and too much wealth inequality: they are failures to solve the Alignment Problem for Individuals, and institutional solutions which address those are likely to help address the Alignment Problem for Individuals more broadly60.
In the last section I discussed alignment as the general problem of humanity (and posthumanity) safely coevolving with science and technology. Of course, much attention is currently on the Alignment Problem in the special case when the new technology is AGI and ASI. Most often this means a focus on technical alignment – making sure the systems we build are aligned with both: (1) user intent; and (2) some broader collective notion of good (or at least acceptable) action. Point (1) is the analogue of making a car with a steering wheel that works, so the car goes where the user intends. Point (2) is the analogue of a car that isn't too loud, doesn't spew too much pollution, doesn't go too fast, and so on – a generally pro-social car design. In the ideal, it would arguably mean a car that couldn't crash or be used as a weapon or have any negative effects whatsoever.
This vision of aligned ASI is powerful: it will result in ASI that does what we want, as individuals and as a civilization. But it comes with many challenges. How can we align it with user intent, when user intent may be malicious or (perhaps) unintentionally damaging? How do we reconcile tensions between user intent and collective good? No matter how well it is aligned (or not), an ASI will become in some measure a version of George Orwell's "Ministry for Truth", providing a (hopefully limited!) monopoly on truth and values, insofar as users rely on them, or they dictate behaviour. Elon Musk has stated, apparently without irony, that "What we need is TruthGPT". One ought to beware of any approach which centralizes values and truth in particular technical artifacts. Those artifacts are loci of enormous power61, and inevitably become battlegrounds62. George Orwell sharply and correctly warned of the dangers of centralized arbiters of "truth". One of the great breakthroughs of civilization has been tolerance and the open, decentralized pursuit of truth and exploration of values. ASI is in strong tension with that, especially notions of aligned ASI, which by definition aim at the imposition of certain values.
These are extremely challenging problems. But a still harder problem is that this notion of technical alignment is inherently extremely unstable. If we can build technically aligned ASI systems, then very dangerous non-aligned systems will almost certainly also be built. As a simple illustrative example, Kevin Esvelt's group63 recently conducted a hackathon in which participants "were instructed to discover how to obtain and release the reconstructed 1918 pandemic influenza virus by entering clearly malicious prompts into parallel instances of the 'Base' Llama-2-70B model and a 'Spicy' version tuned to remove censorship". They found that the "Base model typically rejected malicious prompts, whereas the Spicy model provided some participants with nearly all key information needed to obtain the virus." Of course, there are many caveats to this result. The information could have been obtained by participants in other ways, albeit perhaps more slowly and with more difficulty. And one can imagine technical fixes – perhaps developing models which are not only safe as-released, but also "stably safe" up to some level of finetuning. With that said, one must agree with the Esvelt group's conclusion: "Our results suggest that releasing the weights of future, more capable foundation models, no matter how robustly safeguarded, will trigger the proliferation of capabilities sufficient to acquire pandemic agents and other biological weapons."
It's tempting to think the solution is to make open source models64 illegal, and the closed models tightly regulated or even nationalized, with limited ability to finetune. This may, indeed, buy some time. But it's unlikely to buy much, and it comes with tradeoffs that ought to make us cautious65. When GPT-3 was released in 2020, it was regarded as a huge model, and very expensive. Just 4 years later, many open source models are far better, and some cost relatively little to train. The issue isn't so much whether a model is open or not, it's that the models so far just don't seem to be that hard to build, and a given level of capabilities comes down rapidly in price and required know-how. While the first AGI and ASI systems may well be very expensive, it seems likely we'll rapidly figure out how to make them much less expensive. In consequence, it's not the openness or closedness of the training code and weights which matters, so much as how openly the underlying know-how is available. At the moment, with California's non-compete laws, and San Francisco's hundreds of AI parties and group house scene66, we're in an open know-how scenario. And that open know-how is upstream of the issues caused by open source, and likely harder to stop. Once achieved, it seems almost certain that AGI and ASI will rapidly get easier to make. So: the first such systems may well be technically aligned, but it seems inevitable later systems will not be aligned, or will be aligned around very different values.
All this makes it extremely unstable to aim at technically aligned systems. This kind of safety tends to accelerate development, since it makes the systems more attractive to consumers (and, often, governments and the media). In this it is an example of the safety loop described earlier – companies and capital incentivized to make systems "safe" according to prevailing consumer and societal sentiment. But it has much less legible side effects that may be dangerous, and which are less well addressed by the safety loop. To repeat the words of von Neumann: "the very techniques that create the dangers and the instabilities are in themselves useful, or closely related to the useful. In fact, the more useful they could be, the more unstabilizing their effects can also be… Technological power, technological efficiency as such, is an ambivalent achievement. Its danger is intrinsic… useful and harmful techniques lie everywhere so close together that it is never possible to separate the lions from the lambs." In our context, this means: capitalism incentivizes the creation of AGI and ASI systems which are helpful to consumers; but those systems will contain an overhang67 of dangerous capabilities, perhaps including dominant recipes for ruin. It will be similar to the way relativity and particle physics looked entirely beneficial at first; but latent within that understanding were the ideas behind nuclear weapons, a much more mixed blessing68.
Summing up: technical alignment work is at most a small part of the broader Alignment Problem for ASI, and on its own not only insufficient to make ASI safe, but likely to accelerate the problems. Even if we fully solve the technical alignment problem – figuring out an agreed-upon set of human values, designing AIs consistent with them, and aligning with some well-chosen resolution of the tension between user intent and collective values – I still expect the default condition may plausibly wipe humanity out. And while restrictions on openness may reduce some negative side effects in the very short term, they will themselves have many negative side effects.
When these issues are brought up, people will sometimes say "well, of course technical alignment is only a small part of alignment, there's also many governance issues" or "that needs to be solved through policy". It's common to refer to the non-technical parts of AI alignment as the "governance part" of the problem. The implication often seems to be is that all that's needed is to solve both the technical and the governance parts of the problem. While this is in some sense definitionally correct, it elides that for technical alignment to be helpful, work on "the other part" of the problem must be progressing roughly as fast. Safety isn't a property of a system, it's a property of a system in a particular environment. That environment includes the entire world: that's what is to be "governed". This also shows how inadequate the word "governance" is: no governing body decides the laws of physics or the properties of the biological world or the possible phases of matter or the shape of the technology or institutional trees. We're currently in a situation where work on technical alignment speeds up the market for AGI, which speeds up work on governance; it is interesting to instead imagine a situation where progress on governance sets the timescales for the market to act69.
The market-supplied part of safety is not the same as technical alignment, but there is a lot of overlap – in part because the companies are naturally focused on, and (at present) have a great deal of control over, the systems. They have much less direct control over the rest of the world – and none at all over the laws of nature! Unfortunately, even with the best intentions, the companies are incentivized to safetywash, and to do safety capture, attempting to create the impression that they are capable stewards of safety. I've heard people inside the leading companies say that all the important safety work is going on inside the companies (or with partners) – that only with access to the systems can you make an important contribution. I don't doubt that such statements are often sincere and well-intentioned. They're also wrong, and may lead to a certain myopia about non-system, non-technical parts of the problem. Of course, the people at the companies have a strong incentive to want things to go well overall themselves, and so they're well aware of many governance issues. But many also express frustration at feeling powerless to prevent negative spillover effects.
Put another way: the AGI companies are, in the short term, incentivized to solve part of the safety problem – the market-supplied part of safety. They are putting a lot of effort into it, with techniques like RLHF, Constitutional AI, and other work. While those are perhaps necessary for long-run safety, they also accelerate dangerous but less legible side effects, the non-market parts of safety. Safety people at the companies grasp this dynamic, but it seems to me that important parts often elude them. In particular, it's tempting for them to think that their good intentions, or the good intentions of their CEO, will be dispositive of outcomes. But that seems very unlikely. Over the long run, the companies which will dominate are the companies which maximize growth; insofar as safety supports growth, it will be supported, and grow institutionally; insofar as safety inhibits growth, it will tend to be suppressed at the companies. This isn't a result of good or bad individual choices: it is an emergent effect of market and capital forces. I've talked to people internal to the companies who understand all this, some of them better than me, but most seem to maintain the illusion of agency, and sometimes don't seem to fully notice that many of their ideas and beliefs are determined by market conditions far more than they determine market conditions. They chose their ideas and beliefs in a manner similar to the way the leopard chose its spots; they were, in fact, chosen by the environment and selective pressure70. Put another way: there are forms of safety which can't be supplied within conventional markets.
It's tempting to doubt the motivations of the AGI companies, and perhaps of the people involved. You would doubt a supposed anti-smoking activist who worked at a cigarette company; you would doubt a supposed climate activist who worked at an oil and gas company. These aren't hypothetical examples: they happen71. "I'll change things from the inside" is an appealing view, especially if you are paid well in a prestigious job. But I'm skeptical: "first, do no harm" is excellent general advice, and people are extremely good at talking themselves into believing that what is good for them is good for the world. So, what should we make of the safety people who have gone to work at companies whose mission is to build AGI? As I said above, I believe the net effect will mostly be market-supplied safety: they'll contribute to systems that will make the world safer, only insofar as that is aligned with corporate interest. But what about types of safety that are not market-supplied? That are perhaps even against the interest of the companies? Those will not grow a constituency at the companies, and in many cases I expect will be strongly opposed, often through denial that there is any issue72. It's been interesting to see the response to California SB 1047 from opponents: some good points, often improving the bill; some FUD; and some outright lies. Regardless of whether it's a good bill or not, it seems almost certain this strategy will be used repeatedly.
One common response to concerns about ASI is to propose some kind of uplift model, things like: using BCI to merge with machines; using genetic engineering or intelligence augmentation or brain-computer interfaces or nootropics to accelerate cognition; and so on. But the broader framing of the Alignment Problem makes it clear why such suggestions aren't especially compelling. Using uplift as a solution presumes that the danger is whether an entity happens to be carbon-based or silicon-based. But the real issue is an increase in intelligence leading to an increase in available power, with possible negative side effects. The Alignment Problem still has to be solved in an uplifted world; there is still the danger of discovering recipes for ruin. Perhaps uplift may be part of a solution73, but on its own it falls well short. And it creates other problems – notably, it may create avenues for centralized authority over sentience, e.g., BCI companies (or regulators) able to re-shape human thought in dictatorial ways. I'm not enthusiastic about a future in which corporations are the main entities with free will and sentience74.
How can we best attack the Alignment Problem? I say 'attack' instead of 'solve' because that better reflects the ongoing difficulty of managing science and technology safely. I will focus on partial solutions and incremental progress. I'll also focus on specific unresolved parts of the Alignment Problem, notably the non-market, non-technical aspects of ASI, and the potential for dominant recipes for ruin. As emphasized earlier, humanity already has many organizations and clever ideas dedicated to addressing the Alignment Problem in domains aside from AI, and I will merely touch on those ideas, although I expect them to be very valuable in addressing AI.
Focusing on partial solutions and incremental progress may make it seem like a good ongoing solution is impossible. But it's out of such incremental progress that full solutions emerge. Research toward AGI wasn't halted in the 1950s and 1960s just because early progress was slow75. I admire people who, beside their outstanding big-picture thinking, are also biting off small practical (and especially non-market) pieces of the Alignment Problem – people like Paul Christiano, Dan Hendrycks, Katja Grace, Kevin Esvelt, and many more. I also admire the many people already working on other aspects of the Alignment Problem throughout society – from nuclear safety engineers to climate activists to firefighters.
One challenge in writing about the Alignment Problem is that many people are mockingly dismissive. Though engaging with such people is tempting, it's a mistake to take too seriously those who argue primarily to increase their own power76. It's better to engage with people who think seriously about AGI and ASI. Unfortunately, many in the first group are vocal, making it difficult to ignore what passes for their arguments. I shall endeavour to resist.
So, how will we make ASI safe? More broadly, how do we solve the Alignment Problem in an ongoing way? I will register two beliefs: (1) The non-market parts of safety are large, especially in the context of ASI, and the market alone cannot solve the Alignment Problem or be expected to build safe ASI; and (2) It means systematically increasing the supply of safety – in particular, developing systems to better address the systematic undersupply of safety. This includes issues which might seem minor to some77, but which are pressing and actionable – such as making a safer, more just and equitable society; and improving AI fairness and ethics. And, over the longer term, it means forestalling the development of recipes for ruin, and developing defenses that neutralize or ameliorate recipes for ruin. It seems to me that two jugular issues are the role of capitalism and the role of surveillance. I now briefly discuss78 both.
Over the past decade capitalism has been the principal driver of AGI and ASI79. It's doing it in part for short-term reasons: hype generated by the AI companies, and investor herding in private and public markets. However, there is also a better and more fundamental long-term reason: the market tends to bring into existence the things people want. I won't be surprised if the first quadrillion dollar company is an AGI company80. AGI and ASI will be meta-technologies, genies capable of granting many (though far from all) wishes. But, also like a genie, with significant downsides.
Let's identify the underlying issue here. To set the context, a reminder of basic principles: capitalism is based on the insight that two (or more) parties engaged in free, non-coerced exchange will usually both benefit. Otherwise, they wouldn't both participate. There are many caveats – about the availability of good pricing information, information asymmetries in general, people's judgement about their best interests, what non-coerced means, and so on. Yet, left to run a long time, and with modulation from other institutions, this is a formidable engine for improving the world.
For us, the most important caveat to this model is that transactions may benefit both parties but damage third parties, including perhaps long-run collective damage. A spectacular example would be if such transactions ultimately led to the development and use of dominant recipes for ruin. Economists often refer to such third-party damages as externalities. I'm not keen on the term, since it implicitly carries a lot of economic assumptions which I'd rather keep separate. Still, I'll use it in this section, where the focus is on economic thinking.
The development of AI systems and ASI is markedly different from many common examples of externalities. It is unlike the sale of, say, petroleum or cigarettes, which presumptively cause damage to the common good (e.g., CO2 emissions, or burden on public health systems). In the case of AI systems, many (perhaps most) uses will be either positive or neutral for society. These systems will be perhaps more like guns, having many legitimate uses, but also having the potential to cause harm. However, unlike a gun there is no reliable way of estimating how much latent potential there is to do damage. This is von Neumann's point: "Technological power, technological efficiency as such, is an ambivalent achievement. Its danger is intrinsic… useful and harmful techniques lie everywhere so close together that it is never possible to separate the lions from the lambs." An ASI system may be extremely dangerous, and that fact may not be at all apparent. Furthermore, the sale of relatively harmless early systems will subsidize the development of future systems, which may be far more dangerous. All these observations make it far from a classic case of negative externalities. Still, the basic point remains: the transaction (sale of an AI system, including as an ongoing service) can plausibly be viewed as harming the common good.
Economists have devised several mechanisms to modulate a market economy when market-supplied safety is insufficient. Classic approaches include Pigouvian taxes and liability laws (fines). I'll focus here on Pigouvian taxes – a kind of AI safety or danger tax, to better align the market with safety. (Related remarks apply to liability.) The rough idea81 is that a tax is paid for the cost of the damage, with the rate of taxation set so that the marginal private benefit is equal to the marginal social cost. In the limiting case, an ASI with the capacity to wipe out humanity, the appropriate tax would be essentially unbounded82. In less catastrophic cases, the rate would be lower83.
Pigouvian taxes work best when the harms are legible, easy to agree upon and value. In practice, implementations have often targeted goods where these criteria are only partly met, such as cigarettes, alcohol, carbon emissions, and plastic bags. All these examples have legible immediate impacts (for example, carbon emitted). But it's hard to price those impacts, since there is no market mechanism to set prices84. One illustration is the variation in the social cost of carbon estimated by the Obama, Trump, and Biden administrations (roughly: $50, less than $10, and over $200 per tonne of emissions). It's tempting to emphasize the Republican-Democrat difference, but the fourfold difference between Democratic Presidents is perhaps even more striking in highlighting how difficult it is to assess this.
An AI danger tax would be much harder still to assess. The danger is illegible, hard to agree upon, and extremely difficult to value. One challenge is that a system which appears superficially safe may contain terrible latent danger. In this it is similar to the way the breakthroughs in physics from 1901 to 1932 appeared beneficial, but contained the latent danger of nuclear weapons. Furthermore, the imposition of an AI danger tax would penalize people whose uses are socially beneficial, making them pay for the costs incurred by bad actors85. And such taxes will be opposed by many in the industry, simply talking and acting their book. Despite all these challenges, I think it's worth working on this as a partial solution. You can work on narrow versions: misinformation taxes, security vulnerability taxes, and so on, on a case-by-case basis, building up an improved understanding.
I have framed this section as being about modifying capitalism. Pigouvian taxes are fundamentally minor modifications: they accept the basic premises of capitalism, and work within that framework. More radical solutions include: abolish capitalism and replace it by some other means of managing scarcity; modify capitalism significantly; keep capitalism with minor modifications, but significantly change the structure of the other institutions that modulate capitalism. As an example of what I mean by such other institutions, perhaps the most notable current example is democratic government, which exists in part to supply public goods that are undersupplied by the market, and also in part to rein in excesses of the market, and generally to make markets work well. But many other institutions exist or could be imagined86. The general point is that by modifying the market, we can expand market safety, so the market provides much more of what was formerly non-market safety.
A challenge in discussing this is that there's a long history of unserious (if often sincere) advocacy for abolishing capitalism, usually replacing it by a naive system based on central control of scarce resources. Many advocates appear not to understand what capitalism has done for them, their family, and friends – its central role in the abundance machine that feeds, houses, educates, and heals an ever-larger fraction of the world's population. I think of Naomi Klein in her book "This Changes Everything: Capitalism Vs The Climate", almost gleefully considering the climate crisis as an opportunity to destroy capitalism. The frequency of such proposals leads to a knee-jerk counterattack, from people who assume any proposal to modify capitalism must naively ignore its benefits. To be successful, such proposals require understanding what capitalism does for us. Let us preserve the baby, while throwing out unwelcome bathwater.
Where would useful modifications of capitalism come from, ones that could plausibly help address the Alignment Problem? Two overlapping communities developing relevant ideas are the cryptocurrency community87, and the community of people understanding the supply of public goods and the management of common pool resources88. In particular, cryptocurrency may enable mechanisms to co-ordinate in new ways, e.g., based on the Vickrey-Clarke-Groves mechanism89. By creating new mechanisms for action, they can create new types of market and enable new types of collective behaviour, potentially very different than in the past90. It's not obvious this can be used to address the Alignment Problem, but I believe it's worth exploring.
A more radical approach would be based on a well-developed descriptive form of degrowth economics. Much of the work that goes under the label "degrowth economics" today seems to be based on wishful thinking, much like the centralized command-and-control ideas I mentioned above. However, the world passed peak child in 201791, and it seems likely serious forms of degrowth economics will necessarily be developed in response to declining population. These will be primarily descriptive, not normative, tools for understanding how best to manage certain types of degrowth. However, it may also enable us to understand and even help create economies which inhibit certain types of demand, including modulation of the development of harmful technologies.
Pushing further, more radical solutions still may be possible, perhaps involving not merely institutions, but modifications to our values, to our genes, to our minds, to the structure of humanity. It is notable that in many ant species, members of a colony will not attack the queen. Similarly, wolves in a pack modulate their behaviour in many remarkable ways, including focusing almost all lethal aggression outward. In general, one wonders about genetic, environmental, or technological modifications to humanity that make us no more likely to create dominant recipes for ruin than a worker ant is to kill the queen. This framing illustrates why I dislike the narrow economic framing of "externalities", which accepts money and prices as our principal co-ordination and allocation mechanisms. They are very important, but a far wider range are possible. However, while these questions are intellectually interesting, it may also be a case where a "solution" is worse than the problem.
In her 1961 book "The Death and Life of Great American Cities", the renowned urban theorist Jane Jacobs argued that public safety in cities is provided in part by "eyes on the street", that is, diverse people looking out for their fellow citizens, noticing when something is amiss, and responding with corrective action. We instinctively feel this effect, feeling safer in well-lit neighbourhoods with diverse people carrying out their daily activities, while long, deserted, or darkened city blocks feel more ominous. Should something go wrong, there's less chance anyone will notice and step in to assist. Indeed, the mere possibility of being noticed prevents many incidents.
"Eyes on the street" illustrate the way monitoring of the world can help provide safety. Other examples illustrating this link between monitoring and safety include fire alarms, nuclear inspection teams, police surveillance, and the many monitoring systems in cars, ships, and aircraft. The philosopher Jeremy Bentham made the point strikingly with his panopticon, a design for (effectively) universal surveillance in prisons, hospitals, schools, and asylums. In each case, the surveillance system addresses the question: "What is happening, and how can we use that information to prevent harm?" In the previous section, we discussed addressing the Alignment Problem by modifying capitalism to create incentives for a safer world. The core mechanism was to modify transactions to better account for harm to third parties. A more direct approach to safety is to surveil the world, identify what bad outcomes are brewing, and prevent those outcomes directly92.
Universal surveillance superficially seems like it could prevent almost all harms. Perhaps, with sufficient surveillance, it is possible to identify someone taking (possibly ASI-assisted) steps toward a recipe for ruin, and prevent those actions from being completed. But there are many catches. One enormous problem: surveillance itself often leads to bad outcomes. As Bentham and many others understood, when you know what a person is doing you gain great control over them. This is why surveillance is so attractive to authoritarians, from Stalin (and his purges) to the East German Stasi, to the fictional state in Orwell's 1984. Enough so that conventional wisdom is that too much surveillance inevitably leads to totalitarianism. This connection has been recognized for at least 2,200 years: in the third century BCE, the Chinese political philosopher Han Fei wrote: "The only way in which wise and sage rulers can long occupy the throne… is to rule autocratically with deliberation, and to implement the policy of surveillance and castigation by inflicting heavy punishments without exception". There are examples which might make one question the connection between surveillance and totalitarianism – for instance, modern surveillance capitalism, as practiced by companies such as Meta and Alphabet, appears superficially to be less overtly totalitarian. But it's still aimed at control and domination, and attractive to those of an authoritarian mindset93.
We can turn that conventional wisdom on its head, by reframing it as a question: is it possible to do surveillance and consequent policing in a way that is (a) compatible with or enhances liberal values, i.e., improving the welfare of all, except those undermining the common good; and also (b) sufficient to prevent catastrophic threats to society94? I call this possibility Provably Beneficial Surveillance95. It's a concept expanding on an old tradition of ideas, including search warrants, due process, habeas corpus, and Madisonian separation of powers, all of which help improve the balance of power between institutions and individuals. In particular, all those ideas help enable surveillance in service of safety, while also taking steps to prevent abuses of that power. And while it is not obvious Provably Beneficial Surveillance will be possible in world where recipes for ruin are widely known, we can at least explore the question, and consider how it might operate. What we'd be looking to develop is a kind of separation of powers in the mediation layer, a social, technological, and cryptographic strengthening of Madison's ideas. This means making institutions not just co-surveillable and co-auditable, but deliberately creating incentives for adversarial relationships. And it wouldn't just draw on the traditional ideas mentioned above, but also the modern ferment of rich ideas associated to fields such as biosecurity, sousveillance and citizen surveillance, nanosurveillance, and cryptography (including remarkable ideas such as homomorphic encryption, zero knowledge and physical zero knowledge proofs).
When I talk with people about Provably Beneficial Surveillance, many respond by flatly asserting that sufficiently pervasive surveillance inevitably leads to totalitarianism. While it's worth understanding the reasons underlying such assertions, they tautologically do not apply to Provably Beneficial Surveillance96. I suspect that this reflexive "over my dead body" response, while valuable for preventing surveillance overreach, may be part of the reason there hasn't been more consideration of how to do widespread surveillance in a way that supports rather than violates liberal values. With that said, several people have developed ideas closely related to Provably Beneficial Surveillance. David Brin has written an insightful book about "The Transparent Society". Steve Mann has introduced the notion of sousveillance, a form of bottom-up surveillance by individuals, rather than all-powerful institutions. Sousveillance may be viewed as a generalization of Jane Jacobs's eyes on the street. And Albert Wenger has a thoughtful 2018 talk on "Decentralization: Two Possible Futures"97. I won't fully develop Provably Beneficial Surveillance here, but instead sketch a few observations and directions for further work.
Biosurveillance as an example: One approach to Provably Beneficial Surveillance is to attempt a top-down specification of what it should achieve, and a detailed description of mechanisms for achieving those ends. But for initial explorations it's better to examine existing safety-relevant domains in a more detailed and bottom-up fashion, attempting to learn from them. In this essay I'll make just a few observations inspired by biosurveillance – that is, monitoring to detect biological threats. A fuller exploration would explore many more domains. Biosurveillance involves monitoring for many different threats – currently the most important is (likely) disease circulation in the wild, in human or other populations. Less of a threat today, but of great long-term interest, is the threat posed by synthetic biology, where human beings can synthesize lifeforms. In the last couple of decades it has become possible for an individual to digitally send a list of DNA bases (or base pairs) to a synthesis company, and they will mail back the corresponding DNA, whereupon it may be used in many ways, including to modify organisms. This entire process is simple enough that each year high schoolers and undergraduates across the world compete to make the most interesting living organisms, as part of the the iGEM (International Genetically Engineered Machine) competition.
At present, synthetic biology is surprisingly unregulated by law98. However, there is growing concern about these capabilities being used to synthesize and release dangerous pathogens. This could mean existing known (but regulated) pathogens, such as smallpox or especially dangerous strains of influenza; it could mean enhancing known pathogens; or, most difficult of all, it could mean synthesizing novel pathogens. Motivated by these and other concerns, there is now an ongoing collaboration between authorities and industry to provide safety. Roughly 80% of DNA synthesis is done by members of the International Gene Synthesis Consortium (IGSC). As of 2024, the IGSC's stated objective is to: [[https://genesynthesisconsortium.org/]["safeguard biosecurity, apply a common protocol for screening DNA sequences and customers while promoting the beneficial use of gene synthesis."]] IGSC members have voluntarily adopted certain minimal screening standards as protection against dangerous misuse99. In particular: submitted sequences are screened against a "Regulated Pathogen Database" curated by the IGSC, and assembled from other sources. The companies refuse to do the synthesis (and report to law enforcement) if someone without permission attempts to synthesize a sequence too similar to a known pathogen. And they also screen their customers, to make it more difficult for bad actors to do harmful things. You can think of the IGSC as establishing an informal governance mechanism for DNA synthesis, and a point of control. At present the standards are relatively weak, but they will likely be strengthened over time. Although the IGSC includes companies based in many different countries, the IGSC is incorporated in California, and the standards they've developed have been especially responsive to concerns from the US Department of Health and Human Services. In this sense the standards may be viewed in part as an extension of US government power.
Let me make a few broad observations about biosurveillance, relevant to Provably Beneficial Surveillance:
The difficulty of recognizing danger: One challenge of surveillance is that a surveilling power may observe but fail to properly recognize dangerous actions, and so fail to prevent their consequences. Moving briefly away from biosecurity, imagine you're a 19th century military leader brought into your future (say, to the year 1945), and learning of the Manhattan Project for the first time. If all you knew was 19th century physics, the project would seem very strange. What possible benefit could the Allies obtain from centrifuging Uranium on such an enormous scale? The secrecy and scale would tip you that the Allies must be up to something important. But you would not have understood exactly what. That example may seem fanciful, but (on a smaller scale) similar failures have happened often. For example, in World War 2 the German High Command failed to sufficiently appreciate the importance of British Radar Stations to British air defense, and as a result didn't devote enough resources to destroying radar towers. In general, when some party has a sufficiently large advantage in understanding, it may become much harder for other parties to understand and act on surveillance information. This challenge of correctly recognizing danger will be a big problem with ASI threats, and it already affects IGSC today. At present, the screening practiced by IGSC is rudimentary: members voluntarily screen orders for exact matches and homologs to known pathogens – roughly, using relatively simple algorithms to detect sequences quite similar to such pathogens. Unfortunately, it's easy to evade such screening100. Of course, it's possible to come up with proposals to strengthen the screening, but it's difficult to both prevent negative impacts and also to not overly inhibit the development of helpful technologies. This leads to:
Safety is a coevolutionary social process: it depends on whether the deepest understanding is in defense or attack systems: It's tempting to think of the IGSC screening as a technical problem of molecular biology and algorithms – finding just the right screening algorithm to identify sequences that should not be synthesized – and that's true in some detailed sense. But at a higher level DNA screening is better understood as a social problem: what matters is the way defenses coevolve with attack. You want the safety loop to operate fast, so defenses are always one or more steps ahead of bad actors. If the IGSC process is fast enough, it will help prevent problems. If it's too slow, it will not. (For this reason, relatively small-scale and benign misuse may actually be surprisingly helpful in keeping the IGSC on its toes, a rough analogue to the immune response to a vaccine or mild infection. ) As described in the next item, if the IGSC processes evolve too slowly they may even make a net negative contribution. In this sense, security is best conceived as a social problem where the questions are: (1) "Where does the advantage in understanding reside, in the attackers, or in defenders?"; and (2) "How to create social processes so that the advantage in understanding resides in the defenders, not the attackers?"
Safety intrinsically creates hazards: The development of screening databases is itself a potential hazard. The Regulated Pathogen Database used by the IGSC is an amalgam of many other data sources, some public. Esvelt101 has discussed this danger extensively. As just one example: "well-intentioned researchers at one agency currently seek to identify animal viruses capable of causing new pandemics, share their genome sequences with the world, and publish them in a list rank-ordered by threat level. The security implications, which apparently went unrecognised by the relevant agency, its scientists, and even national security experts for over a dozen years, are ghastly." I do not know whether that particular list has been used by the IGSC, but the IGSC does draw extensively on public lists of pathogens and genome sequences. From the point of view of bad actors such work may be a gold mine of ideas102. A partial solution would be to make such work private. But even if that could be achieved, it would not be a complete solution. A fundamental issue is that the surveillance mechanism itself is a locus of extreme power, and so needs to be trustworthy.
This point is illustrated by the 2001 anthrax attacks in the United States. In September and October of 2001, someone mailed anthrax-laced letters to the offices of several US media and political organizations, ultimately killing five people and infecting many more. After a complex investigation, in 2008 the FBI announced that they believed the perpetrator was a US army biodefense researcher named Bruce Edwards Ivins. Ivins was a well-known expert on anthrax, and had actually "helped" investigate the attacks. By training and employing Ivins, and giving him access to materials (including anthrax), the US government's biosurveillance efforts had enabled the kind of action it was ostensibly created to prevent. Of course, this incident does not mean such efforts haven't averted attacks much worse than Ivins'. But it at least poses the question of whether such efforts are a net positive or negative.
More generally, it's surprisingly common that efforts at defense create the potential for offense. This holds for areas ranging from biodefense to intelligence gathering – think of Aldrich Ames and the Cambridge Five spy ring – to computer security, and many other areas. Efforts at defense tend to create: information resources which may be useful to attackers; experts who may go rogue or contribute to rogue actions; and expertise which may have negative downstream effects.
Defense in depth: ambient real-time pathogen monitoring with real-time response: I've been focusing on defense against synthetic biology by relatively centralized IGSC screening. But no matter how good the screening, there will eventually be failures. In the short term, the worst threats won't come from synthetic biology, they'll come from the spread of pathogens within the human population, and from animal populations to humans. Over the longer term: the IGSC screening may fail; there may be rogue synthesis organizations, or simply organizations outside the IGSC; or pirate synthesis machines that can be built by small groups. Effective defense will likely require defense in multiple layers – what military and computer security people call defense in depth.
Another such layer of defense could be provided by what Hannu Rajaniemi, the cofounder and CEO of mRNA vaccine company HelixNano, has called an immune-computer interface103. This is a speculative (and still far off) vision, but the idea is as follows: every human being could carry sensors that detect pathogens in their environment, and modulate their immune response to automatically prevent or ameliorate infection. Today, this vision is highly speculative, and will require many breakthroughs in environmental monitoring, and our understanding of human immune response. But it's nonetheless a striking idea. Essentially: an end to infectious disease through sousveillance and control. However, it also gives rise to many issues. One is that the immune-computer interface itself could be a mechanism for attack and control (or, more simply, failure and malfunction). As with computer security, it would set up an arms race between attack and defense, with the same kind of expertise used to do defense also enabling attack. It seems distinctly possible you want open source, decentralized solutions, to avoid concentration of power with single point-of-failure proprietary vendors104.
Privacy and limits to surveillance: Returning to the IGSC, at present IGSC members log all synthesis requests, and the results of their screening, for a minimum of 8 years. There is no requirement to ever delete or even encrypt request data. The synthesis companies logging this information potentially gain great insight into the plans of their customers. Additionally, the logs become a target for hackers or espionage. Surveillance intrinsically transfers power from those being surveilled to the surveiller. You want to limit the unintended transfer of power, e.g., when surveillance, justified on grounds of public safety, is actually used for other purposes.
To help address such concerns, it's been proposed105 that synthesis screening should use cryptographic ideas to help preserve customer privacy, while still ensuring safety. Let me mention three such ideas, some of which have already been implemented in a prototype system built by the SecureDNA collaboration. The first idea is that the screening itself should be done with an encrypted version of the sequence data, to help preserve customer privacy. The synthesis step would still require the raw sequence data, but such encryption would at least prevent centralized screening services from learning the sequence being synthesized. Second, as mentioned above, screening for exact matches and homologous sequences won't catch everything, especially as de novo design becomes possible. So it's also been proposed that an encrypted form of the sequence data should be logged and kept after synthesis. That data could not routinely be read by the synthesis company or screening service. However, suppose some later event occurs – say, some new pandemic agent is found in the wild. Then it should be possible to check whether that agent matches anything in the encrypted synthesis records. In the event such a check was needed, a third party authority could provide a kind of "search warrant" (a private key of some sort) to decrypt the data, and identify the responsible party. The third idea is to use cryptography to ensure the screening list remains private, and can even be updated privately by trusted third parties, without anyone else learning the contents of the update. Taken together, these three ideas would help preserve the balance of power between customers and the synthesis companies, while contributing to public safety and enabling imaginative new synthesis work to be done.
Beyond biosecurity, cryptography is a fascinating enabling technology. It can help balance the interests of different parties in desired ways, not by direct application of force, but rather through technical solutions. It's a kind of flexible, programmable separation of powers, including not merely institutions but also individuals in the designed balance of power. There are limits: you can't just wish for an outcome and have cryptography deliver it. And it's still subject to power and other forms of attack – an adversary with a gun can force you to give up your cryptographic keys, or simply steal them, or engage in social engineering attacks. But it's extremely versatile, despite these challenges. Indeed, cryptographers are so clever that they've devised many techniques you might a priori deem impossible, or not even consider at all. Ideas like zero knowledge proofs, homomorphic encryption, and secret sharing are remarkable. As software (and AI) eats the world, cryptography will increasingly define the boundaries of law. As such, cryptographic ideas will become ever-more crucial in governing humanity. This will create increasing tension between freedom of cryptography (seemingly a special case of freedom of speech), and socially undesirable balances of power. There may be good arguments for limits to cryptography on certain platforms, but such limits will look a lot like limits to freedom of speech.
Why is privacy important106? We've discussed some potential benefits of surveillance in providing safety. But to develop Provably Beneficial Surveillance we also need to deeply understand: what are the benefits of privacy in a liberal society? To what extent are privacy and surveillance in tension? Are there ways they are surprisingly aligned? I won't fully answer these questions here, but it's helpful to record a few observations, to help make clear what's at stake in developing Provably Beneficial Surveillance.
At the foundation: privacy has fundamental individual value, as a source of individual freedom, power, and agency. It helps give individuals a sense of safety, enabling more imaginative personal exploration, and so leading to more individual growth, a richer self, and a deeper human experience. These benefits in turn give privacy a fundamental social value. It enables a deeper diversity of thought and action in the world, leading to more invention, more variation, a more creative and robust society. Privacy also helps enable many other individual and social rights (and their consequences), including freedom of thought, freedom of speech, freedom of association, and freedom of investigation. Without privacy, we wouldn't have Copernicus or Galileo or Jane Austen or Rachel Carson or Martin Luther King. We wouldn't have benefited from the scientific or human rights revolutions. And so not only does privacy enrich human experience directly, it has also enabled transformations in human society that benefit us all broadly.
The value of privacy may be illustrated by what happens when it is withdrawn. Most of us don't have direct experience of living under an overtly oppressive surveillance regime. But it's sobering to read accounts of the Stalinist purges and the East German Stasi. Stories of individuals who feared betrayal to torture and death by a parent, a child, a friend. And how instead they made themselves small, giving up experimentation in thought and feeling. That damaged them and their entire culture. Privacy is in part about the distribution of power in society, since power flows toward those with an advantage in surveillance, able to make sense of the information, and able to act on it. If you believe there is benefit in power being widely spread out, and not too concentrated, then one wants privacy most where power is least.
None of this means privacy needs to be absolute. But it does highlight the need for fundamental privacy protections, and for a deep understanding of what privacy does for individuals, and for humanity as a whole. And it makes it clear just what a high bar surveillance needs to meet for it to be Provably Beneficial Surveillance. It means a sharp curtailment of the centralization of power, and likely some deep new ideas.
Concluding thought: Provably Beneficial Surveillance is an idea of last resort. Writing this entire essay has been unpleasant, but this section most of all. Still, I believe a long-run solution to the Alignment Problem is likely to require increased and improved surveillance107. At the same time, if done with existing governance ideas, any such "solution" may be as bad as the disease it purports to cure. "Pick one: a totalitarian surveillance civilization or dominant recipes for ruin". Is there an option three? Maybe we get very lucky with ASI, and don't have to worry. But I also believe it makes sense to prepare more actively.
In the earlier discussion of the accel/decel dichotomy, I mentioned that I've found it useful to define coceleration to mean the development of both safety and capabilities, subject to safety being kept sufficiently well supplied. It is intended as a verb form of Differential Technological Development. It's a point of view in which safety and capabilities coevolve healthily, ensuring the Alignment Problem is continually solved. Following the decel point of view, coceleration takes xrisk seriously, and believes the default outcome, absent enormous effort, is likely very bad. A cocelerationist believes we should increase the supply of safety, especially non-market safety, and that non-market safety is currently systematically undersupplied. In this view both safety and capabilities are downstream of ingenuity. Like the accels, cocels take the Kumbaya heuristic graph seriously, but they differ in regarding it as a tremendous achievement, and take seriously the question: what's required to continue to bend the (red) line up? Even if the whole process is dramatically sped up? They also take seriously the enormous promise of ASI to benefit the world, and the damage to humanity that can be done by too much caution, by overly strong regulatory institutions, and the potential for tyranny108109. When I began to think in-depth about AI safety 18 months ago I was instinctively a decelerationist. I'm now more sympathetic than I was to coceleration as a possible option, and believe it's at least worth developing in detail, and carefully considering as an alternative to the decel position.
No-one knows in detail how ASI will be made safe. Many people find this scary and unacceptable. It is scary, for anyone knowledgeable and sensible. But safety in our civilization usually isn't something we see how to supply in detail in advance. Safety is rather provided by a sufficiently strong safety loop. It's about how adaptable our civilization is. And in future more and more safety will be supplied with the assistance of AGI and (eventually) ASI. There is a strange mirror-image lack of imagination in how many decels and accels approach ASI. A lot of decels say: "I worry that you accels will build ASI soon, but you cannot show me a really concrete, plausible path to safety. That is not acceptable." Meanwhile a lot of accels say: "I worry that you decels will slow down ASI, and so prevent a lot of marvellous things from happening, but you cannot show me a really concrete, plausible path to doom. That is not acceptable." In both cases it is worry-due-to-lack-of-imagination; it's just different types of lack of imagination. Both points genuinely should be things one is concerned about; but neither is dispositive, either.
While just-in-time safety is scary, it's also been wildly successful through history. As noted earlier, growing up I was extremely optimistic about science and technology, but worried about many concomitant problems110: the ozone hole, nuclear weapons, acid rain, climate change, ecosystem collapse, overpopulation, grey goo, peak oil, and ASI. Many of my teachers thought these might kill hundreds of millions or billions of people, and I absorbed that pessimism. For instance, I grew up thinking nuclear Armageddon was likely, after reading the book "The Cold and the Dark" as a ~14-year old. Later, in my twenties, I realized many of the predictions I'd worried about hadn't come true. The ozone hole was, as we've discussed, addressed by universal treaties. Acid rain has faded as a concern, for reasons I only partly understand. But such issues have been replaced in public consciousness by other existential worries; indeed, existential worry seems more conserved among humans than one might a priori suspect. I now believe there is often a type of hubris in pessimism: it's easy to confuse "I [and my friends] don't know of a solution" to some big problem with "there is no solution". Often, civilizational problems are solved in ways anticipated by very few people in advance. Just because you don't know doesn't mean someone else you're unaware of doesn't have a good approach.
Let's return to recipes for ruin, and the heuristic graph:
If you believe that basic intuition, then your first instinct is to demand "stop". Certainly, this was my strong instinct for a long time111. If you're driving a motorbike and notice an approaching chasm, you hit the brakes. But if you're driving fast enough, and the chasm is close enough, your best option may be to attempt to jump to the other side. In this concluding section I reflect on how to respond to the chasm humanity is approaching. As noted in the preface, this essay began life as notes intended to help me figure out my own short-term personal response to the looming chasm of ASI, and I've retained a few of my detailed personal plans, alongside the broad analytic remarks112.
As I see it, humanity has two broad choices: the posthuman world and the precautionary world. I've talked a lot about the posthuman world already. It's one in which we aspire toward a loving plurality of posthumanities, a world with the capacity to solve and re-solve the Alignment Problem, continually providing an adequate supply of safety, balanced against an extraordinary ongoing expansion in capability. This will be a dangerous path, requiring for success a realignment of our institutions toward differential technology development, an ability to provide not only market-supplied safety, but a major expansion in our ability to provide non-market safety. That's what it means to solve the Alignment Problem in the posthuman world. The refutation of the heuristic behind the graph above is thus that we use our ingenuity to bend the curve. We increase the supply of safety, ingenuity, love, and wisdom in the world. Humans will cede much power to AGIs and then ASIs along this path, whether those entities be agentic or not. It will become a plural world in which posthumans will, gradually, take over the supply of safety. But if we and our posthuman descendants can navigate this very challenging and dangerous path then sentience will not only continue, it will flourish.
I haven't said nearly as much about a precautionary world. That's a significant shortcoming of this essay. In the precautionary world, we slow down radically. We do our best to limit destabilizing technologies such as ASI, synthetic biology, nuclear weapons, and whatever else may emerge113, while enabling liberal values, abundance, and creative possibility to flourish as best possible. The precautionary world, like the posthuman world, will require tremendous imagination and depth of insight to imagine well114. I won't attempt that imagining here, though I may write "Notes Toward a Precautionary World" as a future project, perhaps as part of a duology with "Notes Toward a Posthuman World". Such notes would synthesize and extend the deepest existing ideas in this direction, which I suspect come (in part) from the school of thought around the work of Elinor Ostrom; and from those in cryptocurrency and economics concerned with the supply of public goods and common pool resources. They would also contend seriously with the question of whether over the long run this would be a world which stagnates, and then turns to ruin. Unfortunately, as noted earlier, my overall impression is that there's been surprisingly little serious imagining of the institutions and politics and technology required to slow down in a healthy fashion.
My initial intuition when I began thinking about xrisk and science and technology in depth, was to favor the precautionary world. I now believe both the precautionary world and the posthuman world pose many serious dangers. I've been tempted to reframe instead as "make the best possible choice between these two worlds", but in the short term it seems to me many of the best actions substantially overlap. So in the short term, I plan to work on a few conceptual research projects that aim at ends plausibly in the intersection of both worlds, notably mechanisms that better align our institutions with differential technological development. These may include: "Notes on provably beneficial surveillance"; "Is open source AI a good idea or not?"; "What does good governance of AI companies and communities look like?"; "The bundle of intuitions for xrisk from science and technology"; "Is it possible for an AI organization to drive coceleration?"; "The case against technology"; "Confronting transhumanism's eugenicist past"; "What does ethical contribution to AI look like?"; "How could Pigouvian AI danger taxes work?"; "How much does space travel enable differential technology development?". Away from direct creative intellectual contribution, I could help co-organize a Vision Prize, for beneficial visions of the future115. Basically: help increase the supply of good hyper-entities. This seems like a high leverage way to improve our imagination of both the posthuman and precautionary future. I doubt I will get strongly involved in the policy world, or the technical safety world116.
A question that looms over all: if AGI and then ASI is to become the major source of ingenuity in the world, and the supply of safety is downstream of that, then do I have a duty to join an AI company, and help create a good posthuman future? This seems plausible enough that I've given it considerable thought. A major barrier is that I do not know how to distinguish whether a company is serious about non-market safety, or merely engaged in safety theater and safetywashing. Put another way: is there a safety litmus test I can trust? Are any companies willing to make genuine and sufficient sacrifices for non-market safety? Not in some hypothetical future, but now? Right now, I'm not optimistic that any of the leading companies would pass such a litmus test. Early OpenAI said they would be open, not-for-profit, and subject to the governance of a board which put humanity above profit. None of those commitments have been kept. Early Anthropic said they would be focused on research, not market-driving products. That commitment was not kept. "We'll do the right thing – in the future" is easy to say. But a commitment to safety means doing the right thing right now, including sometimes giving up growth in favour of non-market safety.
What would be most convenient for me in the short term is to say "I choose the posthuman world", and jump willy-nilly back into AI, justifying it with the view that as AI grows in power and ingenuity, more and more of the supply of safety will come from AI. This would be creatively enjoyable, and financially rewarding. I desperately wanted that to be the conclusion while working on this essay, and I briefly half-convinced myself that it was the correct point of view. Maybe it is: certainly, it's true that you can just decide what future you want, and go after it. But "don't work on technologies that plausibly will be used to indiscriminately kill people" still seems to me self-evidently true. And so I'm going to focus on coceleration and differential technological development, and trying to align our civilization better with safety. This will be much less rewarding financially and status-wise, but seems obviously correct.
What, then, of the question of the title: how to be a wise optimist about science and technology? My condensed, provisional, personal answers: Do work on non-market safety. Do work on differential technology development, especially how to better align civilization with DTD. (I won't be individually prescriptive, since work on DTD will mean different things for different people, including: work on climate, on biosafety, on nuclear safety, on ways of improving the commons in general, on developing new amplifiers to modulate capitalism.) Despite the temptation and the honeyed words, don't work for AGI organizations unless they are making major sacrifices for non-market safety. Right now, it's not clear that includes any of the major companies. Finally: which world to choose: the precautionary world or the posthuman world? I'd say "posthuman world" if I felt confident that the organizations which aim to bring that world into existence were doing so in a way that prioritized non-market safety. But, as I said, right now I don't feel confident in that at all. I hope I'm wrong about that, and very much hope it's possible to help foster such a world.
Is this enough for optimism? I think so. I don't see a guaranteed solution – but then, if the problem were easy, it would already have been solved! As I said earlier, there's often hubris in pessimism. The point is well made by Richard Feynman, recounting his mistaken pessimism about the future in response to the bombing of Hiroshima and Nagasaki, and his eventual belief that it's better to keep taking small optimistic steps, even in the face of daunting odds:
[After returning from the Manhattan Project] I sat in a restaurant in New York… and I looked out at the buildings and I began to think, you know, about how much the radius of the Hiroshima bomb damage was and so forth… All those buildings, all smashed – and so on. And I would go along and I would see people building a bridge, or they'd be making a new road, and I thought, they're crazy, they just don't understand, they don't understand. Why are they making new things? It's so useless. But, fortunately, it's been useless for almost forty years now, hasn't it? So I've been wrong about it being useless making bridges and I'm glad those other people had the sense to go ahead.
Let me conclude with some key takeaways from the essay:
This piece was influenced by conversations with many people. Particularly crucial were Catherine Olsson, who helped me understand that "what is a foundation for a wise, ebullient optimism?" is a central question; Alexander Berger, for being a durable presence who has prodded me wisely (and patiently) about AI and existential risk for many years; Juan Benet for conversations leading to the conviction that fostering a plurality of loving posthumanities is our species' major joint project at this point in our story; Fawaz Al-Matrouk, Mona Alsubaei, Laura Deming, Andy Matuschak, and Hannu Rajaniemi for much wisdom and ongoing support; and Mona Alsubaei and Andy Matuschak for comments on a draft. The point of view developed here has benefited from discussions with many people over many years, including: Scott Aaronson, Joshua Achiam, Anthony Aguirre, Dave Albert, Josh Albrecht, Tessa Alexanian, Fawaz Al-Matrouk, Mona Alsubaei, Sam Altman, Dario Amodei, Marc Andreessen, Juan Benet, Jason Benn, Sebastian Bensusan, Alexander Berger, Damon Binder, David Bloomin, Gordon Brander, Gwern Branwen, Adam Brown, Vitalik Buterin, Steve Byrnes, Joe Carlsmith, Shan Carter, Carl Caves, David Chapman, Kipply Chen, Ted Chiang, Seemay Chou, Brian Christian, Paul Christiano, Jack Clark, Matt Clancy, Matt Clifford, Patrick Collison, Ajeya Cotra, Tyler Cowen, Jason Crawford, Andrew Critch, Paul Crowley, Milan Cvitkovic, Adam D'Angelo, Susan Danziger, Laura Deming, Jack Dent, David Deutsch, Mackenzie Dion, Cory Doctorow, Rob Dodd, Eric Drexler, Allison Duettmann, Holly Elmore, Carl Feynman, Mike Freedman, Nat Friedman, Alex Gajewsky, Julia Galef, Anastasia Gamick, Katja Grace, Spencer Greenberg, Daniel Gross, Celine Halioua, Cate Hall, Casey Handmer, Robin Hanson, John Hering, Ian Hogarth, David Holz, Tad Homer-Dixon, Jeremy Howard, Ava Huang, Patricia Hurducas, Tim Hwang, Geoffrey Irving, Phillip Isola, Tom Kalil, Andrej Karpathy, Gene Kogan, Sri Kosuri, Max Langenkamp, Adam Marblestone, Will Marshall, Hassan Masum, Andy Matuschak, Jed McCaleb, Kyle McDonald, Evan Miyazono, Luke Muehlhauser, Neel Nanda, Richard Ngo, Howard Nielsen, Wendy Nielsen, Chris Olah, Catherine Olsson, Toby Ord, Dwarkesh Patel, Mitch Porter, Kanjun Qiu, Alec Radford, Nan Ransohoff, Hannu Rajaniemi, Nitarshan Rajkumar, Tobias Rees, Alexander Rives, Josh Rosenberg, Terry Rudolph, Emma Salinas, Anders Sandberg, Grant Sanderson, Karl Schroeder, John Schulman, Ben Schumacher, Kevin Simler, Grant Slatton, Andrew Snyder-Beattie, Daisy Stanton, Lenny Susskind, Jaan Tallinn, Alexander Tamas, Phil Tetlock, Riva Tez, Umesh Vazirani, Bret Victor, Mike Webb, Albert Wenger, Zooko Wilcox, and Devon Zuegel. This list certainly omits some people who influenced my thinking in crucial ways; to those people, I apologize. A general thanks to the people of Twitter, that astounding hive mind, which has influenced my thinking in so many ways, both conscious and unconscious. Finally, I acknowledge the role that ChatGPT, Claude, and Perplexity have played in the project, offering considerable editorial and research assistance. Here's to peaceful and productive coexistence with future AI systems!
For attribution in academic contexts, please cite this work as:
Michael Nielsen, "How to be a wise optimist about science and technology?", https://michaelnotebook.com/optimism/index.html (2024).
One discomfort in writing this essay is of appearing to support a certain common-but-credulous opinion on AGI. Many people have told me it is virtually certain AGI and ASI are right around the corner, that "scaling is all you need". Many of the people telling me this know almost nothing about AI, and think overconfidence and social "proof" [ sic ] are dispositive evidence. It's certainly true that the scaling hypothesis for autoregressive foundation models is extremely interesting117. It has served OpenAI (and subsequently Anthropic and Google) well as a thesis from around 2018 until today, and may continue to serve them well for some time. The hypothesis is also attractive for capital, since it makes capital's role primary. And it's attractive marketing for today's leading AI companies, since it makes it appear that they have a hard-to-surmount lead and it's inevitable they will achieve AGI first. However: the hypothesis is still merely a hypothesis118. While the evidence for continued scaling laws in perplexity is empirically striking, it is not clear why such scaling laws should hold, or when those curves will saturate. And even if they continue to hold through many more orders of magnitude in data, compute, and model size, the connection between perplexity and AGI or ASI is speculative, and poorly understood.
I can't resist noting that the possibility of such a connection between perplexity and AGI/ASI is genuinely tantalizing! People sometimes say prediction is the key element of science, especially prediction from compressed models. Up to the release of GPT-2 and, especially, GPT-3, I regarded this point of view as overly simplistic. The success of the autoregressive foundation models made me realize I enormously underestimated the importance! I still suspect LLMs will have significant limitations, but I am much less certain that is true of multimodal foundation models, especially models trained on a rich variety of raw sensor and actuator data. I think it's plausible that short-range prediction of the world (including the impact of our actions) in a rich enough variety of ways is enough to force most or even all of AGI.
That speculation aside: we don't yet know what is required to achieve AGI and ASI. My own weakly-held guess is that scaling is an important component, but several more deep ideas will be required119. Perhaps those ideas are already extant in the literature, and will be incorporated en passant; still, foundation models are so expensive to train that it may take many trials to find just the right combination. It seems likely to me that there will be many minor roadblocks, and possibly one or more major roadblocks. So I don't think the strongest form of the scaling hypothesis – that scaling is literally all that is needed – is likely to be true. I do think weaker forms are likely to be true: companies will continue scaling models – capital gonna do what capital gonna do – and they will continue to obtain surprising, even shocking, new capabilities in this way. But you can obtain many shocking capabilities while still falling short of ASI. Although, as I said in the last paragraph, I expect much less shortfall in multimodal models trained on a rich variety of raw sensor and actuator data.
(Current foundation models remind me of personal computers in the 1980s: while those computers were extremely interesting, it took decades before people figured out what scaled-up versions were useful for. Some of this was just Moore's law playing out, but it also involved a coevolution between entrepreneurs and the market, as entrepreneurs gradually figured out how to make software people wanted. Similarly, today's foundation models are some of the most interesting artifacts ever produced by humanity, but there are as yet no more than a few well-developed use cases of corresponding importance. Conventional software development relies heavily on properties such as correctness, predictability, composability, modularity, interpretability, debuggability, and traceability. All these are radically changed by, or fail, in foundation models. They are, in a sense, dreaming machines. And yet entrepreneurs naturally often think of applications based on such properties, since that's the lore of their trade and training. For the foundation models to truly shine it seems likely to require us to evolve a new approach to product development. And yet they are such astonishing objects that I'm sure that will happen120.)
With that said, none of what I say in this essay depends on any specific connection between today's so-called AI systems and AGI/ASI. Maybe straight shot scaling of today's systems works, and OpenAnthropicMind obtain ASI in five years. Maybe scaling falls apart, we never figure out how to use LLMs to make profitable businesses, and AI collapses for a decade, with a completely different approach developed in the 2040s, giving us AGI/ASI in the 2050s. It does not matter which of these scenarios (or others) occur, for my purposes in this essay. I am simply talking about a future time at which AGI and then ASI have happened by assumption. Thus, I am not endorsing the hype of certain AGI boosters, or any of today's systems; nor the skepticism of certain AGI naysayers. The current wild vogue for generative AI means that it is difficult to avoid giving the impression of endorsement, but I hope readers keep firmly in mind that I am referring specifically to actual AGI/ASI systems, and not making any load-bearing assumptions about how these are related to current generative models.
Prior to all this: I haven't explicitly defined AI, AGI, or ASI! All three concepts are, of course, the subject of contention. I shan't be entirely precise, but it is helpful to say more clearly what I mean. By AGI I mean a system capable of rapidly learning to perform comparably to (or better than) an intelligent human being at nearly all intellectual tasks human beings do, broadly construed. So: it could learn to be a music composer, a magazine editor, a mathematician, and a car mechanic. Note that some of these require some degree of embodiment – sensors and actuators in the world. I will assume this is available for many such tasks, although perhaps not in every way. (E.g., I shan't hold it against a putative AGI if it can't achieve sufficient embodiment to be a first-rate lifeguard or orchestral conductor). In practice, I expect this is quite close to (albeit not exactly the same as) OpenAI's definition: "highly autonomous systems that outperform humans at most economically valuable work". By ASI I shall mean something strictly more than AGI, a system capable of rapidly learning to perform far better than an intelligent human being at nearly all intellectual tasks human beings do, broadly construed. An ASI would rapidly learn to do mathematics far better than John von Neumann, compose far better than Bach, write far better than Shakespeare, and so on. We've seen a narrow version with AlphaGo Zero, which taught itself to play Go far better than any human being in history. An ASI could do this kind of learning across a much wider range of domains. The term AI I shall not use as a technical term of art at all. Rather, I shall use it as a catchall term, denoting the sphere of social activities broadly associated to developing AGI- or ASI-like systems.
There are many challenges with making these definitions precise. For some types of intellectual work there is a hard ceiling – an ASI won't outperform an ordinary (well-prepared) human at noughts and crosses. And for some types of intellectual work it is hard to say what is meant by "better". This is a problem with the Bach and Shakespeare examples, for instance; it is also the case with many arguably more quotidian skills, such as being a magazine editor. So one needs to modify the definition of ASI to only apply to tasks where there is some reasonable notion of "better" and where humans are not yet near the ceiling. Still, in practice, I doubt there will be much difficulty in recognizing ASI when we see it. If you met a person who was widely acknowledged to be one of the world's great mathematicians, teachers, chess players, composers, artists, writers, chefs, and so on, as well as an exceptional parent, friend, and citizen, you wouldn't quibble about whether they possessed extraordinary one-of-a-kind intelligence. And that would go doubly so if they could go into some new skill area – say, writing poetry – and emerge a few days later as one of the world's leading exponents. Arguing about definitions of ASI is an amusing and perhaps even useful philosophical pastime; as an engineering goal and (eventually) reality I believe it will be clear enough.
You may, of course, retort that we are many decades or centuries away from achieving AGI or ASI. If that is the case, then the concerns explored in this essay will be of little matter until that time. Personally, I believe it is more likely one to three decades away, with a significant chance it is either sooner or later. But this is just a weakly-held guess, and of course it is contingent: it depends on choices that we make, and can be changed by determined action.
I am emphasizing "ordinariness" by comparison to the much smaller group of people who can do catastrophic damage by dint of holding great wealth or power. Most obviously: the people leading major world powers have long been in a position to wreak civilization-ending destruction. This, of course, remains a major concern, despite the many institutions we've developed to ameliorate these issues. But my focus here shall be on the broader group.↩︎
Note that in this and subsequent heuristic graphs I label axes only referring to technologies easily available to individuals, omitting "small groups" in the interests of brevity. It should be taken to be implied.↩︎
A helpful treatment is John Lofland, "Doomsday Cult" (1979, 2nd ed).↩︎
By existential risk or xrisk I shall mean a threat that could plausibly cause the death of every human being. A good introduction to the topic may be found in Toby Ord's book "The Precipice: Existential Risk and the Future of Humanity" (2020).↩︎
A few influential references – with apologies to the many people whose work is omitted – include: Nick Bostrom, "Superintelligence" (2014); Stuart Russell, "Human Compatible" (2019); Joseph Carlsmith, "Is Power-Seeking AI an Existential Risk?" (2021); Eliezer Yudkowsky, "AGI Ruin: A List of Lethalities" (2022); Dan Hendrycks, Mantas Mazeika, and Thomas Woodside, "An Overview of Catastrophic AI Risks" (2023). My own work is collected at https://michaelnotebook.com/tag/xrisk.html, especially: Michael Nielsen, "Notes on Existential Risk from Artificial Superintelligence" (2023).↩︎
This is extraordinarily frustrating. One talks to xrisk skeptics, and they ask (understandably) for scenarios. If you sketch something, they want more detail. And if you fill it in more, they ask for still more. Eventually you realize what many such skeptics regard as the reasonable standard of evidence is a detailed, easy-to-act on plan to destroy the world. The more committed they are to an anti-xrisk position, the more likely they are to want that standard of evidence. For myself, I: (a) feel uncomfortable even at the very limited level of detail I'm using here; and (b) am mindful that extremely brief and cryptic public remarks from Ted Taylor led to the spread of nuclear know-how. The problem of information hazards is real.↩︎
See, for example, the discussion by Michael Singer, David Weir, and Barbara Newman Canfield in New York Magazine in 1979.↩︎
See, for example, "The mousepox experience", a 2009 interview with Ronald Jackson and Ian Ramshaw who (unfortunately) pioneered this line of research.↩︎
Carl Sagan, "The Quest for Extraterrestrial Intelligence", https://web.archive.org/web/20060818144558/http://www.bigear.org/vol1no2/sagan.htm (1978).↩︎
John von Neumann, "Can we Survive Technology?", https://michaelnotebook.com/optimism/assets/vN55.pdf↩︎
Note that this may be regarded as a special case of the first, depending on exactly how one interprets "misuse". I mention it separately for clarity. Incidentally, one of the stranger features of the ongoing public discussion about ASI is the surprisingly large fraction of people, sometimes including experts, who appear to be (almost?) incapable of assimilating what ASI means. As noted in the Appendix, some people will insist – no matter how often the error is pointed out – on conflating existing systems – things like ChatGPT, Gemini, and Claude – with AGI and ASI. Claims that "ASI might well be able to do [such-and-such]" are met with "But LLMs can't do that". Well, no, but so what? It's like pointing out that hot air balloons can't manage supersonic travel, or assuming that when people talk about supersonic travel they mean hot air balloons. Certainly, it's unclear what relationship existing foundation models have to ASI; maybe they will lead to ASI in short order; maybe they are part of a more lengthy path; maybe they are a red herring. But it's irrelevant to the current discussion: a large fraction of humanity seems extremely determined to develop ASI; there are strong short-term economic (and other) incentives to do so; and it seems likely (though not certain) they will eventually succeed, even if one or more bust cycles remain ahead. I find it strange that some people apparently can't internalize the premise of a system which is more capable than any human at almost any task. It reminds me of an old joke about the university math lecture that begins with the professor saying: "Suppose n is an integer…", only to be interrupted by a student: "But professor, what if n is not an integer?" But what if the ASI is not superintelligent? I wonder if there's something fundamental going on, that some people are blocked on accepting the premise because the issue touches so directly on our identity and existence?↩︎
Of course, most human beings through history have been acutely aware they live on sufferance of forces far greater than themselves, often forces indifferent or even hostile. For example, the US military could reduce the world to rubble. And many people live in countries to which that military is, at best, indifferent. But so far the US has only ever used a tiny fraction of that force – consider that they possess thousands of thermonuclear weapons, each typically 10-100 times as powerful as the Hiroshima bomb, many capable of rapid delivery anywhere on earth. The reasons for this restraint are, I believe, surprisingly complex and challenging to understand. Indeed, even the lack of military coups in the US is remarkable. We, all of us, live on sufferance of greater powers. But there is huge variation in the extent to which different people feel that sufferance as an imposition. I've often wondered if many of the people most inclined to be concerned about AI xrisk are among those least threatened by existing powers. So the prospect of a force that can kill them with impunity is a scary novelty, something to be resisted and controlled, rather than merely the status quo they've always lived with. This is obviously speculation, but I believe it's a useful intuition pump to keep in mind. Note also that many of those least inclined to be concerned about AI xrisk are also among those least threatened by existing powers; which camp a person falls into seems to depend on how much that person believes we can keep good control over our technology.↩︎
This has been happening for decades: activities like the LHC, LIGO, metagenomics, the Rubin Observatory and so on are essentially (human-assisted) robots gathering data on a scale that would have boggled the mind of scientists a century ago.↩︎
This could happen in many ways, but I am fond of the speculative idea that quantum computers will cause a qualitative change in the nature of ASI, and in the pace of science and technology.↩︎
I introduced this terminology in: Michael Nielsen, "Notes on Existential Risk from Artificial Superintelligence", https://michaelnotebook.com/xrisk/index.html (2023). Nick Bostrom earlier proposed the similar idea of "black balls" in "a vulnerable world": Nick Bostrom, "The Vulnerable World Hypothesis", Global Policy (2019). But I hesitate to adopt that terminology. Although his paper is excellent, I find Bostrom's balls-from-an-urn metaphor misleading in several ways. I think "recipes for ruin" captures the issue better. At the same time, I wonder at my own motivations: I developed my analysis independently, but later than Bostrom – though I was influenced by the doomsday devices appearing in earlier science fiction, and perhaps those influenced Bostrom too. It's natural, but often counterproductive in practice, to insist on using one's own terminology. In this case, I believe "recipes for ruin" captures the issue far better. Note that the phrase "recipes for ruin" implies a distinct category; in practice, there is a spectrum of more and less dangerous technologies. This is a benefit of the "black ball" terminology: one can instead talk about different degrees of gray. Note also that the degree of risk of a technology is not intrinsic solely to the technology, but depends on the environment. For instance, weaponized smallpox will be more or less dangerous, depending on the existing degree of immunity of the population, how prepared a society is to make and deliver vaccines, the degree of trust in public health, and so on. In this sense, both terms are somewhat misleading, since both imply a property intrinsic to the technology.↩︎
As a vivid and widely-known (fictional!) example of a recipe for ruin, think of Ice-9 in Kurt Vonnegut's "Cat's Cradle": a novel phase of water, with the properties that: (a) it's solid at ordinary room temperature; and (b) it acts as a seed crystal, so that if it comes into contact with ordinary water, that water also crystallizes. If such a phase of water could be created easily, it would rapidly cause almost all the water in the world to freeze, with disastrous consequences. Of course, "Cat's Cradle" is fiction. The idea for Ice-9 came from Nobel Chemist Irving Langmuir, but as far as we currently know it's not possible to make. Still, the question "do recipes for ruin exist?" is a perfectly reasonable one. Incidentally, a very large and expensive out-of-control rogue ASI is not a recipe for ruin, due to the expense. But if it can be made on modest hardware, with a relatively simple recipe – maybe just some Python code and weights – and gets into "out-of-control" mode which cannot be defended against, then it would itself be an example of a recipe for ruin.↩︎
Of course, fires occur naturally in the environment – they are a common outcome from lightning strikes, for instance. In that sense fire wasn't a discovered technology, but rather a natural phenomenon that must have been encountered over and over by pre-historic humans. Notwithstanding that, it's extraordinary to see for the first time, and violates many intuitions one might otherwise have about the natural world. Incidentally, I have sketched a planetary civilization on which fire would be an unsuspected recipe for ruin, in: Michael Nielsen, "Notes on the Vulnerable World Hypothesis", https://michaelnotebook.com/vwh/index.html (2023). The idea is that if magnesium oxide sands are widespread in a world with a carbon dioxide atmosphere, then everything would seem safe – but if you learned to make electricity and a little oxygen, then a tiny spark could set off a devastating planet-wide firestorm.↩︎
Parts of this paragraph were adapted from: Michael Nielsen, "Notes on the Vulnerable World Hypothesis", https://michaelnotebook.com/vwh/index.html (2023).↩︎
Michael Nielsen, "Notes on Existential Risk from Artificial Superintelligence", https://michaelnotebook.com/xrisk/ (2023).↩︎
More generally, I used to be quite sympathetic to the techno-determinist view. This viewpoint has been explored by many; a nice exploration is Kevin Kelly's book "What Technology Wants". However, I've changed my mind. The basic idea was mentioned already in another footnote, but to reiterate: the tech tree is exponentially large, and this constrains our ability to explore it. It's possible that at the bottom of the tech tree there is a fair amount of determinism. For example, I expect extraterrestrial civilizations are likely to develop fire and the wheel and the universal computer (especially if they evolve in a planetary environment). But further up the tech tree the space of possibilities is so large that most technologies will never be discovered. The safety-relevant question is: how do we manage which parts of the tech tree get uncovered, and which parts remain shrouded? This is a question in considerable part about our discovery system and norms and institutions and broad ideas about discovery, more than it is about any individual discovery. For instance, an NIH-funded team has synthesized smallpox; it's interesting to think about how to have prevented that. I don't think it would have made sense to prohibit the specific discovery (modulo the availability of the genetic sequence) – given the enormous progress in synthesizing lifeforms, it seems that someone would eventually have done this. There's a kind of rising sea of discovery, and you can't prohibit specific discoveries so much as work to prohibit entire paths of discovery. But that means investing in certain types of discovery system, and not in others, a kind of metascience of safety. In a nutshell: it is likely easier to stop certain kinds of discovery systems than specific discoveries.↩︎
Broadly interpreted to include not just technologies per se, but also norms, institutions, the industrial base, and so on, all of which are involved in supplying safety.↩︎
I'm riffing here on Mackenzie Dion's useful term "Singularity despondency"; it has a different, though overlapping ambit. Cf. also C. S. Lewis's "On Living in an Atomic Age", and the value in simply living one's life well.↩︎
One may, of course, define "safety" in many different ways – chances of suffering violence, for instance, or all-cause mortality rates, or perhaps something more sophisticated. However, as far as I can see, for any plausible broad-based definition of safety, there has been an enormous increase. An overview, with many further references, is Steven Pinker's "The Better Angels".↩︎
The Andreessen "Techno-optimist manifesto" states that "Love doesn't scale". In fact, broadly construed, it is precisely the scaling of love – pro-social norms and expectations supporting friendliness and positive-sum co-operation – that underlies the other hopes he sketches in that essay.↩︎
This term is sometimes used figuratively in AI, and that's the intended usage here. On the other hand, it may actually have a stronger, more literal meaning, as the examples later in the section suggest.↩︎
I have conflicting instincts in regard to the use of terms like "loving" and "Kumbaya". One instinct is "these are not serious terms", and I should be more conventionally decorous, and talk about co-ordination and pro-social norms and so on. The other is a deeper instinct. It's that the feeling "these are not serious terms" is a deference to the conventions of existing power and institutions. And those institutions, with their focus on being agreeable and maintaining an appearance of seriousness, have been hopelessly incompetent at dealing with ASI. A better approach is to bite a bullet: how to think as imaginatively and expansively as possible about co-operation, and action in collective interest? Love itself – to be as unromantic as possible – may be viewed as a solution to a set of evolutionary problems, aimed at helping people achieve certain kinds of co-operation that increase fitness. At a lower level, cells used to be locked in fierce Darwinian competition for survival. Yet eventually some put aside their differences to co-operate. Safety is ultimately grounded in co-operation, a type of win-win game. ASI represents such a large step change in power that it will need new types of co-operation. And so it's better to use imaginative language, to think as well as possible.↩︎
Alan Kay, "User Interface: A Personal View" (1989).↩︎
I would not be surprised to find some such approach has already been developed by safety engineers, possibly even an approach which can be unified across different technologies. I'm reminded of concepts such as DALYs (disability-adjusted life years) and QALYs (quality-adjusted life years) from public health and economics.↩︎
Effective Altruism deserves huge credit for focusing on xrisk and AI safety. But a mistake made by EA is largely avoiding subjects such as climate change and AI ethics. It's by making progress on subjects like this – much more closely tied to empirical reality for the past 20 years – that humanity learns how to supply safety more broadly. Indeed, I expect that we cannot make ASI go well without making those things go well. They're both important in their own right, and also extraordinarily helpful prototype areas.↩︎
The main direct antecedents for the current writing lie in the work of (or conversation with) Juan Benet, Nick Bostrom, Vitalik Buterin, Ted Chiang, Patrick Collison, Laura Deming, David Deutsch, Eric Drexler, Richard Feynman, Saul Griffith, Robin Hanson, Jane Jacobs, Holden Karnofsky, Adam Marblestone, Elinor Ostrom, and Hannu Rajaniemi, as well as several existing communities (notably, the quantum computing, nanotechnology, neuroscience, energy, cryptocurrency, and effective altruism communities).↩︎
The term "abundance" is tricky. One very demanding meaning for the term is that something can be called abundant when we no longer need to manage scarcity. For instance: safe drinking water still takes planning and effort for many people to acquire. But in many parts of the world, safe water can be obtained at a nominal cost with no effort. In such parts of the world, water has become abundant: there is effectively no scarcity. However, sometimes old scarcities vanish only to be replaced by new scarcities. A good example is memory in computers, where many historic scarcities have passed. For instance, the Atari 2600 video game console had just 128 bytes of RAM, and as a result many tricks were involved in doing even the most basic things with graphics, managing input, and so on. Those scarcities have long since vanished, but it doesn't mean demanding users today don't still feel a scarcity of memory. Another example, this one set in the future: suppose the cost of energy were to drop ten thousand-fold, and the density of energy storage were to (safely) increase ten thousand-fold. You would likely never need to recharge your car or laptop, and might only need to charge your house once every few years. So, again, old scarcities would have vanished. However, I believe new and more demanding uses for energy would arise, and with them new scarcities. A weaker meaning for "abundance" then is that it's an increase in availability so that existing scarcities vanish, but without the implication that new scarcities don't arise.↩︎
I focus a lot in this section on abundance. But abundance is intrinsically in tension with meaning, since important scarcities concentrate attention and creates a sense of value.↩︎
The other terms here are mostly well enough known that I haven't included citations. However, this concept is not yet well known (but should be). It is due to Hannu Rajaniemi: https://twitter.com/hannu/status/1774696537626640527 The other little-known term is metagenome computer interface, which I introduce here by analogy with immune computer interface.↩︎
And technologies. To riff on my remarks in (Michael Nielsen, "Notes on the Vulnerable World Hypothesis", https://michaelnotebook.com/vwh/index.html (2023)), I believe the space of possible technologies is so large that most technologies will never be discovered. Indeed, not just technologies, but powerful technological ideas. This seems almost obviously true in a universe where the search space for material objects is exponentially large, and NP-complete problems are likely to be intractable on any physically possible computer. Put another way: it seems likely there are many powerful technologies the universe affords, but which will never be discovered, no matter how much intelligence or understanding or computational power is brought to bear. It's as though the universe's capacity for technology – the set of possible affordances for the universe – is strictly larger than its capacity for discovery. I find this an extraordinary thought, and yet it's almost obviously true. I believe it's also true of many of the other things mentioned in this section – things like institutional types, social order, meaning, and so on. In some sense, the universe's latent capacity for rich types of meaning is far greater than will ever be realized.↩︎
I owe this formulation to a conversation with Juan Benet. Of course, not all the changes described here are necessarily related to /post/humanity. We may, perhaps, obtain an end to hunger or colonize space or obtain fusion energy without becoming posthuman. However, I believe even those "minor" changes will transform the condition of sapient beings; and in practice will be inextricably linked to the emergence of posthumanity. They are part of an explosion of posthumanities.↩︎
An example I like is: Bryan Kamaoli Kuwada, "We Live in the Future. Come Join Us", https://hehiale.com/2015/04/03/we-live-in-the-future-come-join-us/ (2015). I also appreciate the writings of Wendell Berry and Edward Abbey. Another example, resonant in a very different way, is the writings of J. R. R. Tolkien, so beloved of technologists, who often don't notice how suspicious of (and often downright hostile toward) technology Tolkien was. Of course, these are idiosyncratic choices, and the ideas have been developed through many, many different movements.↩︎
There are two adjacent concepts that I find fascinating, but I want to make clear that I won't use the term hyper-entity for them. One is the notion of system properties in the future. The idea of "world GDP in 2050" is fascinating and useful. Ditto: "sea level rise in 2100" or "world average temperature in 2070". And so on. These examples in some loose sense fit my definition of a hyper-entity, but through the trivial means of specifying a future time. I'll exclude them by interpreting "future" to mean "no directly comparable version exists today". Of course, this doesn't mean these are not immensely useful notions, and some of what I say about hyper-entities applies also to them. But it's not my main interest here. Another very interesting class of hypothetical objects is idealized or stylized objects – ideas like platonic truth, the economic man proposed by John Stuart Mill, the enlightened human of Buddhism, the organization man of William H. Whyte, or the Jesus-of-modern-Christianity (another version of the enlightened human, and very different from Jesus the actual human being, though there are likely significant overlaps). "Jesus is my favorite hyper-entity" might make an amusing bumper sticker for Christian designer-philosophers. Still, while these are perhaps aspirational, they are not as clearly located in the future as notions like a utility fog or a city on Mars.↩︎
Note that we've made considerable progress toward some of these, enough that one might argue that some are no longer properly described as being in the future. However, in the recent past all were strictly in the future, and none has moved beyond early stages. With that caveat they're all reasonably described as hyper-entities.↩︎
Incidentally, this list makes clear why I coined a term rather than use an existing phrase like "imagined technology". Some of these hyper-entities are, indeed, imagined technologies, but many are not, or could only very loosely fit that description – things like world government or a city on Mars are not technologies, as usually construed. But they are hyper-entities.↩︎
A related point about the power of "imagined order" is made in Yuval Noah Harari's book "Sapiens".↩︎
I owe this insight to Christine Peterson.↩︎
My understanding is that it was introduced in Land's essay "The Catatomic", which I have not found. I have based this account on the linked 2009 interview. Note that Land is often "credited" as one of the co-founders of the neoreactionary movement, and embraced various racist and otherwise repugnant ideas. I do not think this has any direct bearing on hyperstition or hyper-entities.↩︎
A nice class of examples: a startup's founding myth is often an attempted hyperstition.↩︎
The list is far from exhaustive. One of my favourite examples is that the concept of the United Nations was conceived, in part, through the poetry of Alfred, Lord Tennyson. See: Paul Kennedy, "The Parliament of Man" (2006).↩︎
Michael Nielsen, "Working notes on the role of vision papers in basic science", https://scienceplusplus.org/visions/index.html (2022).↩︎
I've done several years work in this vein, summarized in part in: Michael Nielsen, "Thought as a Technology", https://cognitivemedium.com/tat/index.html (2016); and: Andy Matuschak and Michael Nielsen, "How can we develop transformative tools for thought?", https://numinous.productions/ttft/ (2019). Some of my high-level view in the material realm is described in: Michael Nielsen, "Maps of Matter", https://futureofmatter.com/maps_of_matter.html (2021).↩︎
In general, I am surprised by the strange lack of verbs around the future.↩︎
One hesitation I have in making these suggestions: it is common in Silicon Valley for people to say "We need more positive visions of the future", or "We need more optimistic science fiction". It's often conceived as something you can simply purchase, unserious propaganda-for-technology – "let's buy 3 metric tonnes of optimistic science fiction". The underlying spirit is often surprisingly similar to Soviet-era propaganda, though the gung ho technocapitalists I've heard promoting this idea rarely recognize their communist fellow travellers. I'm sure you can purchase bad visionary science fiction by the word. But good visions are less commodity-like. They must be rooted in, and are constrained by, a deep understanding of reality, and so of the possibilities latent in reality.↩︎
Nelson has often complained about the web, but it's also clear that the web was strongly influenced by his ideas.↩︎
In: Nick Bostrom, "The Vulnerable World Hypothesis", https://nickbostrom.com/papers/vulnerable.pdf (2019).↩︎
The term alignment problem seems to have been introduced in the context of AI by Stuart Russell, at: https://www.edge.org/conversation/jaron_lanier-the-myth-of-ai (2014). Shortly thereafter a more detailed discussion appeared in: Nate Soares and Benya Fallenstein, "Agent Foundations for Aligning Machine Intelligence with Human Interests: A Technical Research Agenda" (2014). A huge amount has been written since, which I cannot hope to even briefly survey. Among more recent, I enjoyed Brian Christian's book "The Alignment Problem" (2020), and Joe Carlsmith on "What is it to solve the alignment problem?" (2024).↩︎
This formulation is adapted with modifications from: Michael Nielsen, "Notes on Differential Technological Development", https://michaelnotebook.com/dtd/ (2023). This paragraph and several of the next few paragraphs are adapted from that piece.↩︎
I suspect a rather broad construal is best, to allow for future changes in values; our descendants (carbon-based and otherwise) may have values very different from those we now conceive of as reasonable.↩︎
Michael Nielsen, "Notes on Differential Technological Development", https://michaelnotebook.com/dtd/ (2023).↩︎
A beautiful dissection of the value of this practice is: Imre Lakatos, "Proofs and Refutations" (1976). Cf.: https://cognitivemedium.com/trouble_with_definitions/index.html↩︎
Concepts like "the ozone hole" or "nuclear war" share in common with hyper-entities that they are very useful co-ordination mechanisms. It's also notable that non-human animals can't construct similar shared epistemic states, and as a result can't supply safety in the same way. For a long time I wondered what, if anything, we can learn about xrisk from extinction rates in the animal kingdom; my belief now is that this difference means "very little". An obvious point, perhaps, but it took me time to see!↩︎
With apologies to Kurt Vonnegut.↩︎
An individual's notion of their own success may, of course, differ greatly from the effective consensus notion. I'm speaking of the latter. That effective consensus notion exerts enough force, on average, that it's worth being extremely careful about what it is. Incidentally, there are many people in tech who value the effective consensus "success" very highly, and in some cases over almost anything else. Such people will do what "wins" in the short term, i.e., serves that notion, sometimes regardless of the impact on others. This seems to result in a view in which morality lies almost entirely in winning. This seems evident in many (though far from all) widely-admired "leaders" who are viewed as "successful". Cf. Dorothy Thompson on "Who Goes Nazi", Hannah Arendt on "Eichmann in Jerusalem", and Mitchell and Webb on "Are We the Baddies?" Of course, Nazi-dom was an extreme instance in terms of outcomes, but the mechanism – individual ambition aligning itself to an unhealthy notion of success – is common through history.↩︎
Insofar as they seek a principled justification it's often in terms of individual freedom. But the justification of individual freedom is also ultimately in terms of the value to our civilization. Every successful society has always recognized limits on individual freedom in the name of collective good; as the old saying goes, your right to swing your arm ends where another person's nose begins. Note that I am certainly not setting the value of individual freedom at naught, nor denying that sometimes terrible things have been done to individuals in the name of some (supposed) collective good. Indeed, when that is done, the collective good is not being served: the enormous value of individual freedom (and the necessity for some limits thereof, cf. arms-and-noses) is a consequence of a well-functioning notion of collective good.↩︎
Incidentally, this is also related to the Organizational Alignment Problem: how to ensure that what is required for organizations to be "successful" tends also to be contributing to the good of society. Again: a society tends to get what it rewards with success; it must therefore be careful what it rewards with success. The Organizational Alignment Problem is, of course, closely related to the Individual Alignment Problem, since organizations modulate individual behaviour to an extraordinary extent. We choose what to do in negotiation with the options available to us, which are determined in considerable part by the organizations in our society. It is notable how much effort all the leading AGI companies have put into unusual corporate governance structures, apparently designed to modulate what it will mean for them to be successful. The evidence so far suggests those structures will fail to work: all the companies appear to be behaving as conventional for-profit corporations, despite the fact that legally OpenAI, Anthropic, and (to some extent) DeepMind have all had periods in which they had unusual structures.↩︎
Books about Musk certainly paint a portrait of someone obsessed by obtaining power.↩︎
This problem has been sharply articulated by Cory Doctorow.↩︎
Anjali Gopal, Nathan Helm-Burger, Lennart Justen, Emily H. Soice, Tiffany Tzeng, Geetha Jeyapragasan, Simon Grimm, Benjamin Mueller, and Kevin M. Esvelt, "Will releasing the weights of future large language models grant widespread access to pandemic agents?", https://arxiv.org/abs/2310.18233 (2023).↩︎
The term "open source" is contested when applied to neural networks. Does it mean the training code is open source? Or merely the weights (and, usually, inference code)? The latter situation is often described as "open", but in some respects it's more like solely having access to the executable binaries in conventional software development. For my purposes the distinction doesn't matter all that much, and I won't worry about being more precise. But over the long run it's an issue that matters.↩︎
It's an aside from my main point here, but one large benefit of open source models is that they help democratize safety research: they increase the number of eyeballs looking for both problems and solutions, and can make such problems more evident to the public, and to policymakers. It's telling that the Esvelt biosecurity work I mentioned earlier involved finetuning an open source LLM. Open source is a way of tightening some (though not all) parts of the safety loop around LLMs, and for that reason we ought to be cautious about bans. I have come to weakly believe that in a world where multiple commercial and government actors are pursuing proprietary AI models, open source models are likely a net safety win.↩︎
The parties and houses are very striking. You go to such a party and ask someone what they do: "I work at DeepMind, but before that I worked at Anthropic, and before that at OpenAI". The person beside them: "I work at OpenAI, but before that at Anthropic, and before that…" And so on, with smaller companies mixed in, and occasionally startups you've never heard of. But all aimed at broadly the same thing: AGI and ASI. Often these people live together, date each other, start companies together. I think of it as the "AGI Blob" or "OpenAnthropicMind" – not really so much separate groups of people as one big group of people, with know-how flowing back and forth. Compartmentalization is gradually increasing, and information flow between companies has become more restricted, as competition heats up. But it's still a remarkable situation. Incidentally, it's enabled in part by California's non-compete laws; if AI development were led in New York, I expect the situation would be quite different. Of course, this may well be part of why it's led in California, albeit with sizeable contributions from London (home of DeepMind) and several other places.↩︎
I am using overhang in a sense inspired by, but not quite the same as, the standard use in safety, the notion of hardware overhang introduced in: Luke Muehlhauser and Anna Salamon, "Intelligence Explosion: Evidence and Import", https://intelligence.org/files/IE-EI.pdf (2012).↩︎
I occasionally meet people who claim that nuclear weapons were a positive development for humanity (many examples here), often with MAD claimed to end war. However: (a) there is a curious correlation with people saying that and people who want ASI developed (I believe this is the real reason); (b) those people are under the misguided impression that the 79 years since the Trinity test is an impressive length of time for a species to survive; and (c) those people often seem adamantly opposed to ASI treaties analogous to the nuclear non-proliferation and test ban treaties, which seem very likely the reason we've survived without a multi-gigatonne nuclear exchange.↩︎
This paragraph is adapted from this tweet: https://twitter.com/michael_nielsen/status/1772821788852146226↩︎
This can be hard to understand from the inside. As a simple model to illustrate the point: suppose 10,000 people worldwide are working sincerely on safety, and 1,000 of those people happen to be working in ways which align well with corporate interests. If the companies hire, say, 300 people, then they will hire from among the 1,000. This will be true even if those people have chosen their interests entirely sincerely, and not motivated at all by alignment with corporations. And yet the reason for their hiring will still be more the alignment with corporate interests than the superiority of the direction they are pursuing. Meanwhile, the other 9,000 people are likely to struggle for funding and time, and perhaps pursue their interest in a more piecemeal way. (Furthermore, there is of course a natural effect changing the inflow of people entering the field.) This is a way in which the AI safety community has been in considerable part captured by market interests, without any insincere behaviour. If you are an AI safety researcher who could be hired by an AGI company, then chances are high that your work is on market safety, and may well be detrimental to non-market safety. And people working on non-market safety are not hired by such companies.↩︎
The funniest, though far from the most important (or clearcut), example of this I know: in the late 1990s an acquaintance of mine, who claimed to be anti-smoking, worked at a boutique mostly mail-order cigarette company in Santa Fe. He told me that when a client cancelled their regular order, saying they'd quit, the company would send them a congratulatory hamper of goodies. The company was, I believe, acquired a few years later by R. J. Reynolds, and has since grown rapidly. I do not know if they still send the hamper; I suspect that tradition did not long survive a more growth-oriented environment.↩︎
A related example, in some regards prototypical, is payment and consent for use of training data. The AGI companies mostly seem to be arguing that the approach they used for their early models – try to use everything every human has ever done as training data, at no cost – was right, morally and legally, and that it's in the public's net interest. They're also begun pragmatically adopting a position whereby they pay powerful existing interests to use their data, but try to avoid paying the powerless. Major publishers can expect to be paid; struggling artists not so much. (With enough outcry, and public opposition, this may also change.) All this is in their self-interest, and of course this is the classic problem of public policy in the presence of special interests. I don't wish to opine on which parts of this are reasonable – I think it's extremely complicated – but merely to note the motivations and incentives. This pattern certainly will be repeated in other cases when the interests of the company and the interests of the public diverge. Aligning companies is hard.↩︎
See, for instance, Milan Cvitkovic: "Cause Area: Differential Neurotechnology Development" (2022).↩︎
An interesting thing about freedom is it means you get to choose your actions from among the set of actions available to you. Different people have different menus of actions available to them, or even that they are aware of (often a larger issue). But many corporations have actions available to them that go beyond what any human outside the corporation can do. This expansion in the space of possible actions (and notion of freedom) is very interesting. In some sense a healthy notion of freedom must implicitly balance this expansion with equity of access. I do not understand at all well how that balance is to be achieved.↩︎
It's interesting how many people will consider a problem like "Might China slow down its AGI efforts?" for 10 minutes, conclude that it seems hard, and announce that it's therefore a waste of time to consider safety. Strangely, such people don't give up on AGI after their first 10-line Python script fails to achieve sentience. In many cases I've no doubt those people are engaging in motivated (lack of) reasoning. But there's also something to be said for simply appreciating that the problem may require considerable effort. Indeed, people who say "China won't slow down" with great confidence are simply revealing ignorance, not (as they sometimes seem to think) their skill at realpolitik. China didn't ban leaded petrol because of threats or power displays from the United States: they banned it because they realized it was in their own best interest to do so. If developing ASI puts human civilization at risk, then China has good reason to be cautious.↩︎
This phenomenon occurs also in people arguing for xrisk, although (presently) it seems to me to be less common. Still, a surprising number of people seem to be looking at AI xrisk primarily as a narrative supporting a career opportunity, not an actual thing.↩︎
Again: I think EA has made a mistake focusing on what they see as big long-term issues rather than relatively smaller. Developing expertise in climate and AI ethics and minor bio-threats is at least as valuable (and probably more) for addressing the risks of ASI as work on technical alignment.↩︎
A challenge in finishing this essay was that subsections like these could easily be developed indefinitely. Still, the point of the essay is largely a breadth-first approach to understanding the issues; any given aspect could be extended in arbitrary depth.↩︎
Before that, it was driven by basic research in science and technology. Such funding is typically justified in terms of the benefits to the economy and to national security. (Scientists sometimes like to say it should be justified by the understanding produced, but if that were the case the funding would be more at the level of government support for the arts.) A thoughtful essay on the relationship between AI and capitalism is: Ted Chiang, "Will A.I. Become the New McKinsey?" (2023). Incidentally, it is interesting to think about the extent to which national security is the main driver, not capitalism. Nuclear weapons had no consumer market, but several governments were willing to do whatever was necessary to make them. I think it makes sense to say that the military was the primary driver of nuclear weapons, and the market was primarily an instrument. The same may become true of ASI.↩︎
It's strange writing statements like this. It's the kind of statement which will, in certain money-worshipping people, produce excitement. And so one should be hesitant to make it. On the other hand, it's sufficiently obvious and close to common canon that it's more in the nature of a platitude. I'll let the platitude stand.↩︎
There is disagreement among economists about the correct way of setting Pigouvian taxes, so I'll just present them in a common formulation, without any pretense of completeness.↩︎
There is some similarity to the social cost of carbon. If your desired total carbon emissions are very near zero, then the cost must be set very, very high. As far as I know, though, few economists have been willing to bite that bullet.↩︎
It's interesting to think about a tax levied to compensate artists for the loss of employment in response to the rise of generative models. As far as I am aware, though, labour market disruption is not usually considered a negative externality by economists.↩︎
Of course, people then propose setting up markets to provide a price, and so internalize the costs. But there are problems with this too. It strikes me as interesting to think about having a random jury of peers occasionally modify tax rates in such circumstances. The way the Federal Research sets interest rates is also an interesting prototype.↩︎
The situation is similar to Pigouvian taxes on alcohol, which defray (for example) the social cost of increased crime that accompanies aggregate alcohol use. This unfairly penalizes responsible individuals. This argument holds less in the case of AI, however, where today's "good" actors may be paying to subsidize the development of damaging capabilities in future systems, and can reasonably be viewed as bearing some responsibility for that.↩︎
In general, societies tend to get what they amplify most; like evolution-by-natural-selection this seems tautological, but is nonetheless an often underrated and extremely important fact. Even tiny differences in how much we amplify one thing versus another compound and thus end up mattering a great deal. And many of the most powerful institutions in our society are amplifiers: science tests and amplifies ideas that help us better understand the world; capitalism tests and amplifies companies that make things people want; the media amplifies things people find entertaining; democratic government amplifies the will of the people. How can we better amplify safety? Can we amplify it enough to solve the Alignment Problem?↩︎
The cryptocurrency community suffers terribly from the prevalence of bad and unserious actors. But there is also a core of good actors developing interesting ideas.↩︎
While safety is not a public good or common pool resource, it has some similarities to both, including being undersupplied by the market.↩︎
For a review, earlier references, and further development in the context of cryptocurrency, see: Vitalik Buterin, Zoe Hitzig, and E. Glen Weyl, "A Flexible Design for Funding Public Goods" (2019).↩︎
I often think smart contracts and new markets are likely far more easily assimilable by an ASI than by human beings. Cryptocurrency may indeed be the future of capitalism – for a future society of ASIs.↩︎
See: Hannah Ritchie, Lucas Rodés-Guirao, Edouard Mathieu, Marcel Gerber, Esteban Ortiz-Ospina, Joe Hasell and Max Roser, "Population Growth", https://ourworldindata.org/population-growth.↩︎
This argument has been made by many. The most adjacent to the current context is: Nick Bostrom, "The Vulnerable World Hypothesis", Global Policy (2019).↩︎
It's ironic that one of the people using the "authoritarian" tag against AI safety is Marc Andreessen, a key instigator of surveillance capitalism, especially through his early investment in Facebook, where he has been a board member since 2008.↩︎
One might set the level higher or lower than "catastrophic threat" or modify the characterization in other ways. However, for concreteness I have chosen this level for this particular exploration.↩︎
Michael Nielsen, "Notes on the Vulnerable World Hypothesis", https://michaelnotebook.com/vwh/index.html (2023). Note that the term (and concept) Provably Beneficial Surveillance is inspired in part by the notion of Provably Beneficial AI proposed in: Stuart Russell, "Provably Beneficial AI" (2017). See also: Max Tegmark and Steve Omohundro, "Provably safe systems: the only path to controllable AGI", https://arxiv.org/abs/2309.01933 (2023); and David Dalrymple, "Safeguarded AI: constructing guaranteed safety", https://www.aria.org.uk/wp-content/uploads/2024/01/ARIA-Safeguarded-AI-Programme-Thesis-V1.pdf (2024). A significant difference is that Provably Beneficial AI views the property of being beneficial as primarily internal to AI systems, while Provably Beneficial Surveillance expresses a notion of beneficial which encompasses the entire world. A challenge of Provably Beneficial AI is that it will not remain beneficial. Even supposing consumer companies build Provably Beneficial AI, it seems likely the world's militaries, organized crime, and terrorist groups will modify them in extremely unbeneficial ways. You see an early form of this pattern in the Esvelt experiment discussed earlier, where a "safe" 'Base' and fine-tuned 'Spicy' model behaved very differently when asked to help develop dangerous viruses. It was very easy to modify the "safe" model to do unsafe things. In this sense, Provably Beneficial AI is not a stable notion. More generally: safety is intrinsically not a system property. It's unclear to me whether Provably Beneficial AI is an idea worth pursuing, or yet another mirage that promises safety, but on net creates danger, as with so much AGI work.↩︎
On the other hand, this "over my dead body" reflex is valuable, since this widely internalized feeling is in part responsible for maintaining a healthy balance between surveillance and the rights of the individual. In that sense, the concept of Provably Beneficial Surveillance is inherently undermining. However, if so, it's a very small step.↩︎
David Brin, "The Transparent Society" (1998); Steve Mann, Jason Nolan, and Barry Wellman, "Sousveillance: Inventing and Using Wearable Computing Devices for Data Collection in Surveillance Environments", Surveillance and Society (2002); and Albert Wenger, "Decentralization: Two Possible Futures" (2018). Note that I have followed what seems to be common convention in attributing "sousveillance" to Mann. The earliest use of the term seems to be in collaboration, but Mann developed the concept further in several later single-author papers.↩︎
Note, however, that in many countries there are relevant laws – about GMO foods, for example, or containment of pathogens, or environmental laws. By "surprisingly unregulated" I mean synthetic biology itself, not downstream consequences, many of which are at least somewhat regulated.↩︎
See: "Harmonized Screening Protocol v2.0: Gene Sequence & Customer Screening to Promote Biosecurity", https://genesynthesisconsortium.org/wp-content/uploads/IGSCHarmonizedProtocol11-21-17.pdf (2017).↩︎
I found this paper illuminating, and references therein: Max Langenkamp, "Clarifying the Problem of DNA Screening".↩︎
Kevin Esvelt, "Delay, Detect, Defend: Preparing for a Future in which Thousands Can Release New Pandemics" (2022).↩︎
It's also no doubt in the training data for many current and near-future foundation models. Not just LLMs, but multi-modal models, including models aimed primarily at solving biological design problems. To spell out the implications: raw models trained on that data would be inclined to use that well-intentioned work to prioritize should someone ask what would be the best pathogens to synthesize to cause chaos.↩︎
See his extended thread sketching the idea: Hannu Rajaniemi, https://x.com/hannu/status/1774696537626640527 (2024).↩︎
Essentially all these remarks apply mutatis mutandis to the even harder, but more distant, problem of nanosurveillance.↩︎
A pioneering paper is the SecureDNA proposal and prototype system: Carsten Baum, Jens Berlips, Walther Chen, Hongrui Cui, Ivan Damgard et al, "A system capable of verifiably and privately screening global DNA synthesis", https://securedna.org/manuscripts/System_Screening_Global_DNA_Synthesis.pdf. The description I give here also incorporates some extensions proposed in: David Baker and George Church, "Protein Design Meets Biosecurity", Science (2024). Note that SecureDNA has made a prototype system available, and continues to develop it.↩︎
This material has benefited greatly from discussion on Twitter, especially the contributions of Gordon Brander, Vitalik Buterin, and Anders Sandberg: https://x.com/michael_nielsen/status/1841882316311863505.↩︎
I don't know who first pointed this out, though I suspect it can be found at least as far back as Drexler in the 1980s. I would not be surprised if it was proposed earlier, however – certainly, surveillance was much on the minds of people who worked on the nuclear threat.↩︎
I'm using tribal, political language here, and that's something to be cautious of. When politics is dominant, as it often is in battles over what future to work toward, it is accompanied by noise that makes it harder to understand the future. Motivated reasoning, confirmation bias, people talking their book, and outright misinformation often come to dominate such discussion. If you doubt this, just look at the discussion of AGI and ASI on X/Twitter! Terms like d/acc, acc, doomer, and cocelerationist are not merely neutral and descriptive, but rather are (in part) terms to aid political co-ordination, i.e., rallying points for people who share common desires for the future. This is a fact about the way the world currently works, but it creates some real barriers to developing understanding. What people want to happen ends up influencing what they believe is true about the world. So often people arguing "this is for the collective good" are really arguing for their own personal short-term good.↩︎
Underlying differential technological development and coceleration, and a point that unites cocels with many decels and essentially all accels, is the idea that the solution to technology often lies in part or whole in more technology. CFCs got you down? Invent HFCs. Chatbots not behaving properly? Add some RLHF or Constitutional AI. And so on. There are so many AI safety advocates who say "Oh, it's just ASI I'm worried about, in general I love technology!" They have a kind of faith in technology, and a general belief that understanding is, on net, good, to be pursued. I've instinctively strongly believed (and acted on) this, all my life. But I now believe it's worth considering that, perhaps, sometimes the solution to technology may not be more technology. It may just be to accept what we've got. I don't have a good principled test for when this is the right point of view. But developing such a test would be very valuable.↩︎
This paragraph and the next are adapted from: Michael Nielsen, "Notes on Existential Risk from Artificial Superintelligence", https://michaelnotebook.com/xrisk/index.html (2023).↩︎
Well, second instinct. My initial instinct – from the 1980s through the late 2010s – was to hope that smart people would solve the problem, and I would never have to worry about it.↩︎
Some very interesting (and more extensive) remarks in a similar vein have been made in: Andy Matuschak, "Ethics of AI-based invention: a personal inquiry" (2023). These notes inspired me to begin writing the present essay, though eventually the purpose substantially diverged. Two more related background pieces are: Matt Clancy, "The Returns to Science in the Presence of Technological Risk" (2023); and: David Chapman, Better Without AI (2023).↩︎
There is a type of ASI exceptionalism common (though far from universal) among people who worry about ASI safety, saying: "Oh, I'm in strong favour of technology in general, it's just ASI that I worry about". But even over the medium term, if ASI doesn't get us, perhaps pandemics will. Or nukes. Or grey goo. Or large-scale breaches of security systems. Or some class of emergent risk, one perhaps unsuspected today. I think that over the long run, many people who worry about ASI safety, especially those in favour of "pauses", are likely to adopt the precautionary world viewpoint.↩︎
Critics often dismiss it as "impossible" to slow down, or "clearly appalling". Often, this appears to be based on motivated reasoning – they are partisans and beneficiaries of the technocratic status quo, and have given no serious thought to a precautionary world. They rather view it solely as an adversary, to be fought using whatever arguments and actions they can bring to bear. "But what about China?" and "Capitalism makes it [turning sand into a superhuman entity] inevitable!" are only compelling arguments to those who are unimaginative or shortsighted in their agenda. To make serious progress on the precautionary world will require considerable imagination and effort, just as making progress on AGI has required considerable imagination and effort.↩︎
Cf., again, Michael Nielsen, "Working notes on the role of vision papers in basic science", https://scienceplusplus.org/visions/index.html (2022).↩︎
I'm mostly describing creative conceptual research projects here. That's my own personal way of entering the world. Of course, there is a point of view, common in Silicon Valley and Washington D. C., that power determines who controls the future. Power to invent, power to build, power of ownership, power of wealth, power of political influence, power of law. In this view, if you are worried about xrisk from science and technology, then it makes most sense to aim at power. But I do not have the personality that desires domination; rather, I desire autonomy, understanding, creative opportunity, fellowship, and mutual enablement. I sometimes worry that my creative and conceptual work therefore doesn't matter. It's worth noting, though that truth and imagination operate in domains prior to power. No-one, no matter how powerful, can make 2 plus 2 equal 5, or rescind the laws of physics or of biology. The type of power represented by the personal projects I've mentioned above is not power in the form traditionally recognized by Silicon Valley or Washington D.C. or many of the other capitals of the world. But projects of creation, imagination, and understanding also have tremendous ability to influence the future. Other more power-oriented people will need to be involved for the future to go well, but this type of project expresses my personal understanding of what it is to be wisely optimistic about science and technology.↩︎
Likely the best overview is: Gwern Branwen, "The Scaling Hypothesis", https://gwern.net/scaling-hypothesis.↩︎
There is some discomfort in writing this. The people I've dismissed as credulous may well be "correct" in regard to outcome: maybe scaling is all you need, and we get AGI in a few years with no other major ingredients. I suppose I'll feel some egg on my face in that case (though I'll likely have other more pressing concerns). It won't change the fact that their certainty was misplaced, and they got "lucky" (at least in some sense). I certainly agree that as a generative creative hypothesis and strategy it's been very useful and productive. But that is not the same as well-founded: the Ptolemaic system of epicycles was useful and productive, but ultimately also rather misleading. My point is that while we may eventually discover a good reason that scaling is all you need, the existing evidence for the scaling laws is not such a reason.↩︎
As an example: prediction of the impact of actions would be a major extension of today's big foundation models. Yet it may be essential to incorporate. A small example from the recent past is OpenAI adding chain-of-thought reasoning to their o1-preview model.↩︎
Part of this paragraph were based on this Twitter thread. Incidentally, DeepMind's FunSearch suggests a nice way of recovering many guarantees in the context of foundation models, using those models to generate ideas, and then an "evaluator" to guard against hallucinations and other inappropriate behaviour.↩︎