
Differential technological development (DTD)1 is the idea that humanity should focus on reducing the development of dangerous technologies, and accelerate the development of safety-enhancing technologies. The term (though of course not the concept) originates in a 2002 paper by Nick Bostrom2. It's been the focus of especial interest in recent years in connection with several advanced technologies, including synthetic biology and artificial superintelligence (ASI)3. In an earlier set of notes4 I sketched a reformulation of the Alignment Problem as the "problem of aligning the values and institutions of a liberal society (including, crucially, the market) with differential technology development". The purpose of such an alignment is to give us the enormous benefits of technology, while greatly reducing existential risk, and also preserving or enhancing the values we hold most dear.
In these notes I will:
A question I don't address, but which is important: to what extent is DTD different from older ideas – from fields ranging from safety engineering to sustainability and so on? Obviously there is considerable overlap, but I shan't engage systematically with the question.
The notes are part of a series in which I work out my thinking about existential and catastrophic risk from technology, including (but not only) ASI and biotech. Other entries in this series may be found here. (This current set of notes is, frankly, particularly in-the-weeds, mostly focused on identifying crucial problems, but making frustratingly little progress on solving them.) To date, these are all rough preliminary thinking. They're intended principally for my own use, although a few people have been kind enough to say they've benefited from the notes. I hope my understanding will eventually mature enough to make it worth writing a more polished and better developed overview; if so, it will also appear at the above link!
The description of DTD in Bostrom's original 2002 paper is brief and interesting enough to be worth quoting and commenting on in full. I omit only the inline citations in the original text; they may of course be found in the original paper.
If a feasible technology has large commercial potential, it is probably impossible to prevent it from being developed. At least in today’s world, with lots of autonomous powers and relatively limited surveillance, and at least with technologies that do not rely on rare materials or large manufacturing plants, it would be exceedingly difficult to make a ban 100% watertight. For some technologies (say, ozone−destroying chemicals), imperfectly enforceable regulation may be all we need. But with other technologies, such as destructive nanobots that self−replicate in the natural environment, even a single breach could be terminal. The limited enforceability of technological bans restricts the set of feasible policies from which we can choose.
This paragraph (and its sequel) appears to me overly dismissive of the partial solution of bans on harmful technologies. The locks on my house won't stop a determined burglar, but there is still considerable benefit in having the locks; they are a partial solution. Technological bans are certainly imperfect, as the paragraph correctly points out, but they are worth consideration as part of a DTD strategy. Although nuclear power overall wasn't stopped by opposition, it seems plausible that certain types of nuclear technology have been stopped (or considerably delayed) by the opposition, despite having large commercial potential. Of course, whether this is good or bad for humanity is another question – I merely offer it as a plausible example of a de facto ban of a feasible technology with large commercial potential. Strikingly, it wasn't achieved by a direct legislative ban, but rather by an overall slowing of technological development – the space of possible technologies simply hasn't been explored nearly as much as it might have been. Put another way, the approach hasn't been to go for a direct ban, but rather to use opposition to make the cost of developing certain technologies sufficiently high that they in practice aren't developed. You might retort that this means they don't have "large commercial potential", and thus aren't a counterexample to the argument of the paragraph. But in spirit it's a counterexample: the point may be restated as being that commercial potential is far from intrinsic to the technology, but can be radically affected by other things, including public sentiment. In practice, I think bans are worth considering as part of the DTD armamentarium.
Bostrom defines DTD in the next paragraph. I've added emphasis here to make the definition more prominent:
What we do have the power to affect (to what extent depends on how we define “we”) is the rate of development of various technologies and potentially the sequence in which feasible technologies are developed and implemented. Our focus should be on what I want to call differential technological development: trying to retard the implementation of dangerous technologies and accelerate implementation of beneficial technologies, especially those that ameliorate the hazards posed by other technologies.
I shall return to this definition in the next section, and identify several important ambiguities.
In the case of nanotechnology, the desirable sequence would be that defense systems are deployed before offensive capabilities become available to many independent powers; for once a secret or a technology is shared by many, it becomes extremely hard to prevent further proliferation.
True, although sometimes there are important monopolies that prevent proliferation, at least for some time period. An interesting current example is the company ASML, which has a de facto monopoly over advanced photolithography. This monopoly has been exploited by the US, who pressured ASML to restrict sales to China in 2018; similar restrictions continue in 20245. Several people involved in semiconductor manufacturing have told me that ASML's advantage here is enormous, and surprisingly hard to replicate. I don't doubt that it can be replicated, but the timescale might be well over a decade, perhaps several. It would be interesting to better understand the conditions responsible for creating such a monopoly; several people have confidently told me "the reason"; however, they've told me different reasons, which suggests it's not so obvious.
In the case of biotechnology, we should seek to promote research into vaccines, anti−bacterial and anti−viral drugs, protective gear, sensors and diagnostics, and to delay as much as possible the development (and proliferation) of biological warfare agents and their vectors. Developments that advance offense and defense equally are neutral from a security perspective, unless done by countries we identify as responsible, in which case they are advantageous to the extent that they increase our technological superiority over our potential enemies. Such “neutral” developments can also be helpful in reducing the threat from natural hazards and they may of course also have benefits that are not directly related to global security.
Such "neutral" developments do have, as Bostrom says, considerable benefits. But they also implicitly take the side of technocracy against non-technocrats; it's an inherent redistribution of power within a society. Put another way: an assumption underlying DTD is that the cure for technology is more technology. Most of my readers are probably technocrats, and some perhaps don't see this as an issue6. Still, I think this movement of power into technology is an important underexamined element of DTD. It's a way in which people favoring DTD are very similar to people favoring almost totally unimpeded advance in technology.
The next paragraph is remarkable, especially in light of recent (as of 2024) discussion of ASI:
Some technologies seem to be especially worth promoting because they can help in reducing a broad range of threats. Superintelligence is one of these. Although it has its own dangers (expounded in preceding sections), these are dangers that we will have to face at some point no matter what. But getting superintelligence early is desirable because it would help diminish other risks. A superintelligence could advise us on policy. Superintelligence would make the progress curve for nanotechnology much steeper, thus shortening the period of vulnerability between the development of dangerous nanoreplicators and the deployment of adequate defenses. [ not obvious at all – if the offenses are helped more by ASI than the defenses, then ASI simply makes the situation worse.] By contrast, getting nanotechnology before superintelligence would do little to diminish the risks of superintelligence. The main possible exception to this is if we think that it is important that we get to superintelligence via uploading rather than through artificial intelligence. Nanotechnology would greatly facilitate uploading.
In a nutshell, the argument is: work on ASI is DTD, because it reduces risk from nanotech! Both Eric Drexler and Bill Joy are cited in the paper; Joy is thanked in the acknowledgments. I suspect few people today would regard work on ASI as DTD, though perhaps I am wrong about that. I wonder how much the availability heuristic determines what is regarded as DTD and what is not? I.e., lots of people circa 2002 were worrying publicly about nanotech risk, fewer about ASI risk; today, the reverse is true, and so opinions about what is DTD have changed. For myself, I'm gradually coming to think it at least plausible that developing and using ASI for DTD may be absolutely essential. It's an unsettling prospect; I'm reminded of Mario Andretti's remark that "If everything seems under control, you're not going fast enough."
Other technologies that have a wide range of risk−reducing potential include intelligence augmentation, information technology, and surveillance. These can make us smarter individually and collectively, and can make it more feasible to enforce necessary regulation. A strong prima facie case therefore exists for pursuing these technologies as vigorously as possible. As mentioned, we can also identify developments outside technology that are beneficial in almost all scenarios. Peace and international cooperation are obviously worthy goals, as is cultivation of traditions that help democracies prosper.
It's fascinating to see surveillance listed as a risk-reducing technology, since so many see it as a tool of tyranny. I have briefly discussed elsewhere the possibility of provably beneficial surveillance7, but that is currently a speculative design possibility. I expect that by default surveillance will increase risk, not decrease it. Bostrom, at least in 2002, appeared to believe the reverse. This underscores the considerable ambiguity in what counts as DTD.
Recapping, Bostrom's 2002 definition of DTD: trying to retard the implementation of dangerous technologies and accelerate implementation of beneficial technologies, especially those that ameliorate the hazards posed by other technologies. He gave a similar, slightly more elaborate definition in his 2019 paper on the Vulnerable World Hypothesis8:
Retard the development of dangerous and harmful technologies, especially ones that raise the level of existential risk; and accelerate the development of beneficial technologies, especially those that reduce the existential risks posed by nature or by other technologies.
People often abbreviate these definitions as something like: work on defensive technologies in preference to offensive. This seems quite straightforward at first, but as the discussion in the last section already suggests, it's often hard to say what counts as DTD and what does not. One person's offensive technology is another person's defensive technology. I've already briefly mentioned ASI. Let me give five additional examples to illustrate the ambiguity. You don't need to personally accept the ambiguities; indeed, in talking over examples like those below, I've often found people rejecting any claim of ambiguity. But, crucially, different people reject the claim for different reasons. Some people will say "obviously a brain-computer interface (BCI) is defensive"; others "obviously BCI is offensive". My experience is that there's a lot of disagreement like this, from well-informed and thoughtful people, which suggests digging beyond surface reasons for such disagreement.
At least some (and maybe all) of these concerns may seem like pedantic nitpicking. I do not think so: I think they are a major problem. Increasingly, funding decisions are being made to fund work on DTD. It would be (extremely) unfortunate if those decisions inadvertently create more problems than they ameliorate. Making good, useful definitions really matters. Poor conceptual foundations often lead to bad outcomes12. Three major problems seem to me to be:
These issues make me wonder: is DTD well enough defined to be a useful category? When we're talking about current technologies, it's often reasonably clear whether or not a technology increases or decreases risk. For instance, widespread investment in flame retardant building materials, or in improvements in aircraft safety engineering, are clearly examples of DTD. However, the purpose of introducing the term DTD is to help think about the broad long-run effects of investing in particular new technologies. In those cases, what counts as DTD and what does not is often a very complicated question. It's tempting to throw up one's hands and say: "It's foolish to attempt long-rang foresight like this, with so many contingencies. Better to adopt a just-in-time approach, responding to imminent problems, or problems where we have really strong models".
I don't have a strong, satisfying conclusion here. I do have two partial conclusions. The first is that I should spend some time searching for other abstract categories that might serve many of the same purposes DTD was introduced to address, but not suffering some of these shortcomings. I've made some progress on this, but it's as yet too in-the-weeds to report here. The second is a general caution around the use of DTD. Whether a given line of work is DTD needs to be regularly re-evaluated. It requires independent evaluations from diverse sources. It's interesting to ponder whether tools like prediction markets can be useful in making the evaluation of future risks. And simply to do more in-depth historical surveys, to figure out which technologies had surprising positive or negative consequences.
As mentioned in the introduction, in my notes on the Vulnerable World Hypothesis, I gave a rough reformulation of the Alignment Problem as "the problem of aligning the values and institutions of a liberal society (including, crucially, the market) with differential technology development". I want to revisit that reformulation in the light of the above discussion. I'll make some modest improvements, and then consider the relationship to the conventional formulation of AI alignment. While this reformulation appears quite different from standard formulations of alignment in AI, as I shall explain below it has some significant advantages: (1) it automatically entails the solution of the standard AI formulation; (2) it also addresses some crucial problems not addressed in the standard AI formulation; and (3) it does this by more correctly identifying the underlying causal factors. A few observations:
Let's consider the relationship to AI alignment. An early statement of the AI Alignment Problem was by Stuart Russell in 201414, where he stated it as:
No one in the field is calling for regulation of basic research; given the potential benefits of AI for humanity, that seems both infeasible and misdirected. The right response seems to be to change the goals of the field itself; instead of pure intelligence, we need to build intelligence that is provably aligned with human values. For practical reasons, we will need to solve the value alignment problem even for relatively unintelligent AI systems that operate in the human environment. There is cause for optimism, if we understand that this issue is an intrinsic part of AI, much as containment is an intrinsic part of modern nuclear fusion research. The world need not be headed for grief.
Shortly after that formulation, Nate Soares and Benya Fallenstein published "Agent Foundations for Aligning Machine Intelligence with Human Interests: A Technical Research Agenda"15:
We call a smarter-than-human system that reliably pursues beneficial goals "aligned with human interests" or simply "aligned." To become confident that an agent is aligned in this way, a practical implementation that merely seems to meet the challenges outlined above will not suffice. It is also necessary to gain a solid theoretical understanding of why that confidence is justified. This technical agenda argues that there is foundational research approachable today that will make it easier to develop aligned systems in the future, and describes ongoing work on some of these problems.
Many (not all) the people working on AI alignment today are working on projects that fall recognizably within (or closely adjacent to) the scope of these formulations. There are, of course, many problems with these formulations, well known both to people working on the problem, and to critics. One broad class of problems relates to the difficulty in specifying and agreeing human values or human interests in any precise form. There is, of course, considerable disagreement between cultures, between individuals, and (indeed) even within individuals about what counts as human values or human interests. In a nutshell: what should an ASI be aligned with?
A second broad class of problems is what we might call the stability problem: even if we can satisfactorily solve the Alignment Problem for some particular AI system, that does not mean it will be solved for all AI systems. Just because the AI system you construct respects human values does not mean they will also be respected by the AI systems your enemies construct. This is especially important since today's frontier AI systems, requiring enormous teams and resources, can often be outperformed a few years later by tiny teams with limited resources. Given the very considerable interest in AI from military organizations – indeed, much pioneering AI work was funded by organizations such as DARPA – it seems unlikely that all advanced AI systems will respect human values.
Now, my formulation of the Alignment Problem as "the problem of aligning a liberal society so it strongly prioritizes DTD, while preserving liberal values" seem superficially almost unrelated to AI risk. But it has many benefits, and (correctly formulated) would: (a) entail a solution of the AI Alignment Problem; (b) address many of the issues with the conventional formulation of the AI Alignment Problem; and (c) would also address issues beyond AI, including bio risk, climate risk, nuclear risk, security risk, and, I expect, many emergent classes of risk, as yet unknown. In particular, successful AI alignment work is an example of DTD. And insofar as our society prioritizes DTD, it must prioritize AI alignment and slow down or pauses capabilities that hurt AI alignment. But it goes further than that: if the stability problem is actually the main threat, then it means we must actually prioritize the stability problem over anything else, including the (conventional) AI Alignment Problem16. Of course, how to achieve this is not at all clear! As mentioned earlier, I've elsewhere proposed a solution, perhaps partial, based on the idea of provably beneficial surveillance.
For all these reasons, I've taken to thinking of this formulation as the strong Alignment Problem. Note that it still suffers some issues: (1) it's ambiguous about just how strongly to prioritize DTD; (2) it doesn't specify what values of a liberal society ought to be immutable (as opposed to ones that merely happen to appear in ours); (3) it suffers from the ambiguities I've identified in DTD. All three of these can (and should) eventually be addressed. Still, I've found this reformulation extremely helpful.
There are certain kinds of DTD humanity does really well, where our society has already achieved alignment. And there are other kinds where we are far from achieving it. The implicit viewpoint of DTD is in some tension with the conventional market view. In that view, new technologies are developed, and safety is then supplied in response to consumer demand. The world's first commercial jet aircraft was the de Havilland Comet. Three Comet aircraft crashed in the first year; while Comet lingered for a while, of course it never really recovered. However, other jet manufacturers played close attention, and rapidly learned to make much safer aircraft. Similarly, the switch from refrigerators using ammonia to CFCs was a case of the market working well to reduce (though, unfortunately, not eliminate) risk. In these cases there is a strong and rapid safety loop operating: when risks are borne immediately and very obviously by the consumer, the market is aligned with safety, and our society does DTD well. It's capitalism as a safety amplifier. We do safety best of all when the danger immediately and spectacularly impacts the consumer, as in the case of Comet. It is perhaps unsurprising that modern airlines are extraordinary paragons of safety17.
By contrast, when no consumer is bearing an obvious immediate cost, our society tends to have much poorer institutions for doing DTD. In those cases markets may amplify technology whose risk exceeds it's benefits. This occurs when the risks involve: externalities; long time lines; are illegible or hard to measure; when they tend to be diffusely shared, perhaps impacting the commons; when it is hard to establish any kind of property rights in the harm. Those of economic mindset will sometimes simplify this down to "externalities", but this is far too great an oversimplification. Nonetheless, insofar as collective safety can (imperfectly) modeled as a public good, we'd expect it to be undersupplied by the market.
I grew up being told I'd likely die due to18: nuclear war; climate change; acid rain; the ozone hole; or one of several other ailments. For the most part these issues were not (or only partly) addressed through market mechanisms. Instead, we've had to build bespoke non-market mechanisms to close the safety loop. Economists tend to favor Pigouvian taxes – and one can imagine general safety taxes being used to address the Alignment Problem, aligning the market with DTD19 – but many of the actual solutions so far have come via other means, often some hybrid of governmental and open-source-bazaar style20. A society gets what it amplifies most. Like evolution-by-natural-selection this seems near-tautological, but is extremely important. Even tiny differences in how much we amplify one thing versus another matter a great deal, and many of our most important institutions are amplifiers. Science tests and amplifies the ideas that help us better understand the world. Capitalism tests and amplifies companies that make things people want. Media amplifies things people find entertaining. How can we better amplify differential technological development?
It has been widely noted by economists that worldwide economic growth appeared to change character circa 1970. This has been memorably dubbed "the Great Stagnation" by Tyler Cowen21. The Great Stagnation is reflected in many ways, including in much reduced global total factor productivity (TFP) growth, often interpreted by economists to mean that the rate of technological innovation is slowing down. The reason for the Great Stagnation is debated. Robert Gordon[fn:Gordon] has argued that a big contributor is that the most important platform technologies can only be invented once, and it just so happens most were invented (or became widespread) over the period 1870 through 1970. This includes things like the internal combustion engine, refrigeration, aeroplanes, and so on.
Another possible contributor is the gradual rise of institutions and norms which actually slow down innovation. Things like lead-in-gasoline, Asbestos, DDT (not to be confused with DTD!), and CFCs were all introduced as miraculous new technologies, with relatively little pushback or oversight. Today, in many domains there are much more challenging regulatory gauntlets to be run. This is perhaps most famous in the case of the US FDA and EPA, but it is reflected around the world, and across multiple domains. Here's a list of a few key events — I've taken a US-centric view here, since it's been the dominant world power over the last 80 years; it is, however, interesting that many of these have (roughly contemporaneous) analogues in many other countries:
It seems plausible that the Great Stagnation is really the initial stage of a Great Realignment22, in which we gradually move toward solving the Alignment Problem. We may trade off some degree of growth for better institutions for dealing with risk. As a very rough caricature, we might say that up to around 1970 the general societal attitude toward safety was rather blase. And since then we've been gradually moving more and more toward a situation managing tradeoffs between safety and technological innovation23.
It is tempting to view these processes as being in opposition. One sees this sometimes expressed in naive calls to "accelerate", from people who view "safety" as the enemy; and also in naive calls for "safety", from people who seem to discount any benefit in acceleration, and view technological progress as the enemy. There is genuine tension there, but ideally it's positive sum; the trick is to find ways of managing that tension, so you get maximal benefit from both. I believe we have not yet found the best institutions for managing the tension.
One sometimes-stated "solution" to the AI safety problem is to give up on human chauvinism, and to celebrate the emergence and perhaps even the eventual dominance of posthumanity. "I for one welcome our new Posthuman Overlords" is a common tongue-in-cheek sentiment; so too is the variant "Welcome to our new ASI Overlords". Positions along these lines have been espoused by people such as Larry Page and Juergen Schmidhuber. Here, for example, is The New York Times recounting a conversation between Larry Page and Elon Musk, in which Page espoused the view that favoring humanity over AI was "specieist":
Humans would eventually merge with artificially intelligent machines, he [Page] said. One day there would be many kinds of intelligence competing for resources, and the best would win.
If that happens, Mr. Musk said, we’re doomed. The machines will destroy humanity.
With a rasp of frustration, Mr. Page insisted his utopia should be pursued. Finally he called Mr. Musk a “specieist,” a person who favors humans over the digital life-forms of the future.
I suspect some of the people saying things along these lines are saying it mostly to be edgy. I suspect also that some believe it, sometimes rather strongly; indeed, I have some sympathy for elements of the view24. It's worth taking the viewpoint seriously, and seeing if it can be made to hold up.
The key point: any posthuman successors will need to solve the Alignment Problem. That is, they will face almost exactly the same problem we face today. Actually, they will likely face a more challenging version, since their environment may contain many more powerful technologies. This is not certain: perhaps some extremely powerful safety-enhancing technologies will be developed, which make the situation much easier for our posthuman successors. But I suspect it's likely they will face even greater challenges than we do today. In general, the following heuristic diagram, from 25, captures something about the fundamental issue:
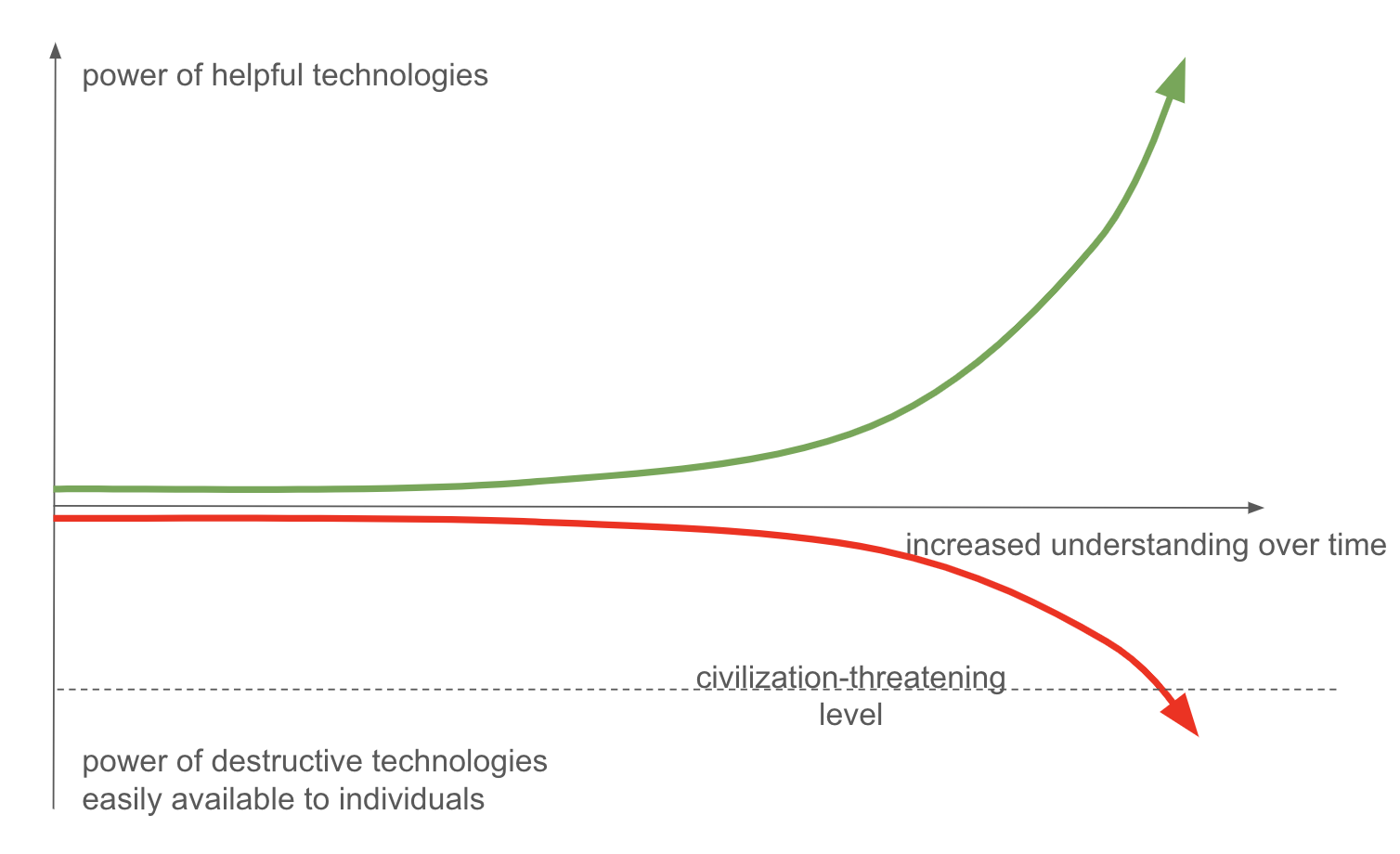
I find this heuristic compelling. That said: I'm given some pause by the considerable amount of work suggesting the world has gradually become more safe over the past few centuries26: lower murder rates, lower burden from disease and malnutrition, and even a gradual drop in warfare. Naive extrapolation suggests that things are likely to get better in a future of yet more powerful technologies. I don't know how to reconcile these two points of view; it seems important to do so.
In 2019 I asked on Twitter what people were individually doing about climate change. I received (mostly) very thoughtful responses from roughly 150 people. A surprising number of people said that while they were very concerned about climate change, they were not personally doing anything directly beyond voting. Several offered arguments whose gist was: "Sure, I'm worried about climate change, but why should I cut down on my personal carbon impact, when that does nothing to address the underlying causal factors, which are actually systemic, not individual? I'd rather limit myself to doing things like voting, which contribute to changing the systemic factors." In this view, many common actions, like reducing flying or automobile use, are imposing a personal cost, but only treating a symptom, not the underlying "disease".
It's a striking response. While I certainly don't completely agree, it highlights an important point about DTD in general: to try to identify and address the underlying causal systemic factors, not merely symptoms. In particular, three very interesting questions to ask:
Let me make a few higgledy-piggledy observations, addressed at some mix of these three questions27. This is (of course) not at all complete. Particularly acute is the omission of conventional safety engineering.
These notes were somewhat frustrating to write. They contain not so much solutions as better-formulated problems. Still, that's valuable, and I made a little progress toward solutions. Key points to take away:
This note is to make a crucial point which was not distilled sharply enough in the first release of these notes, on January 13, 2024. Our civilization doesn't prioritize DTD strongly enough – and so will fail to solve the Alignment Problem – because the safety loop is working poorly for many important classes of risk. It works well when consumers bear highly legible risks. But it often works poorly when a technology damages the commons, affects third parties, or when dealing with long-term, illegible, diffuse, or hard-to-measure risks. That's why I discussed tools for collective action, provably beneficial surveillance, and related ideas, as partial solutions in that direction. If a society gets what it amplifies most, then we need to find ways of amplifying DTD much more forcefully, to address risks where the safety loop works poorly. That's what is required for us to address the Alignment Problem. So, again: how can we much more rapidly amplify differential technological development?
In research work, please cite this as: Michael Nielsen, "Notes on Differential Technological Development", https://michaelnotebook.com/dtd/index.html (2024).
Thanks to Josh Albrecht, Fawaz Al-Matrouk, Alexander Berger, David Bloomin', Vitalik Buterin, Brian Christian, Patrick Collison, Susan Danziger, Laura Deming, Anastasia Gamick, Tim Hwang, Andy Matuschak, Hannu Rajaniemi, and Albert Wenger for conversations about these subjects.
I will use the abbreviation DTD for the most part through these notes. I've noticed in myself and some others a tendency to say "differential technology development" rather than "differential technological development", perhaps because "technology" is a concrete noun (albeit being used as part of an adjectival phrase to modify "development"), where "technological" is a rather abstract adjective. Given my use of DTD the point is perhaps moot, but I must admit a strong preference for the term "differential technology development".↩︎
Nick Bostrom, "Existential Risks: Analyzing Human Extinction Scenarios and Related Hazards" (2002).↩︎
There is far too much work to even give a brief overview here. A broad piece that I am especially partial to is: Vitalik Buterin, "My Techno-Optimism" ,https://vitalik.eth.limo/general/2023/11/27/techno_optimism.html (2023). My notes are at: https://michaelnotebook.com/vbto/index.html.↩︎
Michael Nielsen, "Notes on the Vulnerable World Hypothesis", https://michaelnotebook.com/vwh/index.html (2023).↩︎
See, e.g., Cagan Koc and Jennifer Jacobs, "US Pressured Netherlands to Block China-Bound Chip Machinery", https://www.bloomberg.com/news/articles/2024-01-01/us-pushed-asml-to-block-chinese-sales-before-january-deadline (2024).↩︎
A good discussion of this is: Neil Postman, "Technopoly" (1992). Note that this sympathy to technocracy is widely spread among people with apparently very different views of ASI: "e/acc, doomers, EAs, VCs, researchers, safety people, AI startups, etc. All are united by a sense of agency over, and broad belief in, technology, even when they disagree on details of how it is best developed. And yet many people in the world don't have that same sense of agency over technology; in some cases, they have little agency, technology is something done to them".↩︎
Michael Nielsen, "Notes on the Vulnerable World Hypothesis", https://michaelnotebook.com/vwh/index.html (2023). Cf. also Albert Wenger's talk https://www.youtube.com/watch?v=lBUPEv6KlnM, David Brin's "The Transparent Society" (1998), and ongoing work on sousveillance.↩︎
Nick Bostrom, "The Vulnerable World Hypothesis", https://nickbostrom.com/papers/vulnerable.pdf (2019).↩︎
Brain hackers will be a thing.↩︎
There is a largw literature on this. A brief and recent lay survey is: Alicea Hibbard, Investigating the Smallpox Blanket Controversy (2023).↩︎
Robock and collaborators have written many articles on concerns about geoengineering. A helpful and relatively recent summary is: Alan Robock, "Benefits and Risks of Stratospheric Solar Radiation Management for Climate Intervention (Geoengineering)" (2020).↩︎
I have, for example, previously argued that the notion of a probability of doom may incorrectly bias people – including central people – toward a fatalistic view of ASI development. I've also been one of many people arguing that certain AI alignment and safety work has plausibly sped up ASI, and may have had a negative impact. Both points are discussed in: Michael Nielsen, "Notes on Existential Risk from Artificial Superintelligence", https://michaelnotebook.com/xrisk/index.html (2023).↩︎
Marshall McLuhan, "Understanding Media: The Extensions of Man" (1964).↩︎
Stuart Russell, at: https://www.edge.org/conversation/jaron_lanier-the-myth-of-ai (2014).↩︎
Nate Soares and Benya Fallenstein, "Agent Foundations for Aligning Machine Intelligence with Human Interests: A Technical Research Agenda" (2014).↩︎
AI companies often argue that to make progress on alignment it is necessary for them to build and align better systems. They're correct for the conventional formulation of the AI Alignment Problem. But this is also likely to be strongly destabilizing, since it will lead to much more capable and non-aligned systems. In this sense, they are arguably working against the solution of my reformulation of the Alignment Problem.↩︎
When I say this, people sometimes retort with comments pointing to recent high profile instances of problems, e.g., the run of problems Boeing has had. This unwittingly demonstrates the point. Boeing is (correctly!) being held to an extraordinarily high standard, one so that even incidents resulting in no loss of life receive very wide and extended coverage. By contrast, automobile manufacturers receive almost a free pass by comparison, and consequently automobiles much more dangerous. To be clear: they also benefit from this safety feedback loop, but it's not as strong.↩︎
This paragraph adapted from: Michael Nielsen, "Notes on Existential Risk from Artificial Superintelligence", https://michaelnotebook.com/xrisk/index.html (2023).↩︎
Elinor Ostrom, among others, has emphasized the difficulty of doing this for hard-to-measure-or-demarcate harms: Elinor Ostrom's, "Governing the Commons" (1990). Thanks to Albert Wenger for reminding me of this issue.↩︎
It's tempting to use extinction rates among animal species to think about extinction risk for humans. But humans are the only species that has any kind of non-trivial safety loop. It is, in my opinion, one of the most interesting differences between humans and other species.↩︎
Tyler Cowen, "The Great Stagnation" (2011). Cf also Peter Thiel, "The End of the Future" https://www.nationalreview.com/2011/10/end-future-peter-thiel/ (2011).↩︎
This framing was suggested to me in part by Patrick Collison.↩︎
A lovely evocation of this is by Stewart Brand: https://www.youtube.com/watch?v=YIZw5cT84ZM&ab_channel=AhmedKabil↩︎
Certainly, I don't want to see society frozen as is; I love the idea of change and growth. As Douglas Adams has wrily observed, it's arguable that the automobile is already the dominant lifeform on Earth. We can imagine posthuman futures in which current humanity's descendants live happily as part of a society of minds vastly more diverse than today, a plurality of posthumanities.↩︎
Michael Nielsen, "Brief remarks on some of my creative interests", https://michaelnotebook.com/ti/index.html (2023).↩︎
See, e.g., Steven Pinker, "The Better Angels of Our Nature" (2011).↩︎
Cf. also: AJ Kourabi, "What is differential technological development?", https://www.ajkourabi.com/writings/what-is-differential-technological-development↩︎
Michael Nielsen and Kanjun Qiu, "A Vision of Metascience", https://scienceplusplus.org/metascience/index.html (2022).↩︎
Milan Cvitkovic, "Cause Area: Differential Neurotechnology Development", https://forum.effectivealtruism.org/posts/Qhn5nyRf93dsXodsw/cause-area-differential-neurotechnology-development (2022)↩︎
Jed McCaleb, "We Have to Upgrade", https://www.lesswrong.com/posts/vEtdjWuFrRwffWBiP/we-have-to-upgrade (2023).↩︎